Introduction
Cohen’s Kappa is a measure of the agreement between two raters, where agreement due to chance is factored out. We now extend Cohen’s kappa to the case where the number of raters can be more than two. This extension is called Fleiss’ kappa. As for Cohen’s kappa, no weightings are used and the categories are considered to be unordered.
Formulas
Let n = the number of subjects, k = the number of evaluation categories, and m = the number of judges for each subject. E.g. for Example 1 of Cohen’s Kappa, n = 50, k = 3, and m = 2. While for Cohen’s kappa, both judges evaluate every subject, in the case of Fleiss’ kappa, there may be more than m judges, and not every judge needs to evaluate each subject; what is important is that each subject is evaluated m times.
For every subject i = 1, 2, …, n and evaluation categories j = 1, 2, …, k, let xij = the number of judges that assign category j to subject i. Thus
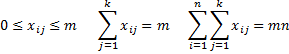
The proportion of pairs of judges that agree in their evaluation of subject i is given by
![]()
The mean of the pi is therefore
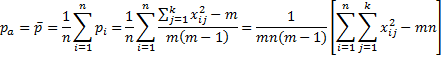
We use the following measure for the error term
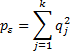 where
where
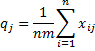
Fleiss’ Kappa and Standard Error
Definition 1: Fleiss’ Kappa is defined to be
![]()
We can also define kappa for the jth category by
![]()
The standard error for κj is given by the formula
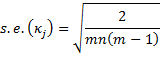 The standard error for κ is given by the formula
The standard error for κ is given by the formula
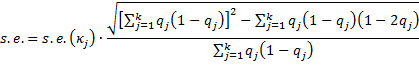
There is an alternative calculation of the standard error provided in Fleiss’ original paper, namely the square root of the following:
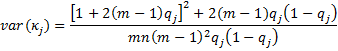
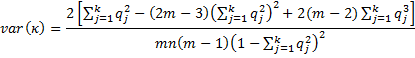
The test statistics zj = κj/s.e.(κj) and z = κ/s.e. are generally approximated by a standard normal distribution. This allows us to calculate a p-value and confidence intervals. E.g. the 1 – α confidence interval for kappa is therefore approximated as
κ ± NORM.S.INV(1 – α/2) * s.e.
Example
Example 1: Six psychologists (judges) evaluate 12 patients as to whether they are psychotic, borderline, bipolar, or none of these. The ratings are summarized in range A3:E15 of Figure 1. Determine the overall agreement between the psychologists, subtracting out agreement due to chance, using Fleiss’ kappa. Also, find Fleiss’ kappa for each disorder.

Figure 1 – Calculation of Fleiss’ Kappa
For example, we see that 4 of the psychologists rated subject 1 to have psychosis and 2 rated subject 1 to have borderline syndrome. No psychologist rated subject 1 with bipolar or none.
Other Formulas
We use the formulas described above to calculate Fleiss’ kappa in the worksheet shown in Figure 1. The formulas in the ranges H4:H15 and B17:B22 are displayed in text format in column J, except that the formulas in cells H9 and B19 are not displayed in the figure since they are rather long. These formulas are:
| Cell | Entity | Formula |
| H9 | s.e. | =B20*SQRT(SUM(B18:E18)^2-SUMPRODUCT(B18:E18,1-2*B17:E17))/SUM(B18:E18) |
| B19 | κ1 | =1-SUMPRODUCT(B4:B15,$H$4-B4:B15)/($H$4*$H$5*($H$4-1)*B17*(1-B17)) |
Figure 2 – Long formulas in worksheet of Figure 1
Note too that row 18 (labeled b) contains the formulas for qj(1–qj).
The p-values (and confidence intervals) show us that all of the kappa values are significantly different from zero.
Finally, note that in versions of Excel after Excel 2007, you can use NORM.S.INV instead of NORMSINV and NORM.S.DIST(H10,TRUE) instead of NORMSDIST(H10).
Worksheet Function
Real Statistics Function: The Real Statistics Resource Pack provides the following function:
KAPPA(R1, j, lab, alpha, tails, orig): if lab = FALSE (default) returns a 6 × 1 array consisting of κ if j = 0 (default) or κj if j > 0 for the data in R1 (where R1 is formatted as in range B4:E15 of Figure 1), plus the standard error, z-stat, z-crit, p-value and lower and upper bound of the 1 – alpha confidence interval, where alpha = α (default .05) and tails = 1 or 2 (default). If lab = TRUE then an extra column of labels is included in the output. If orig = TRUE then the original calculation for the standard error is used; the default is FALSE.
For Example 1, KAPPA(B4:E15) = .2968 and KAPPA(B4:E15,2) = .28. The complete output for KAPPA(B4:E15,,TRUE) is shown in Figure 3.
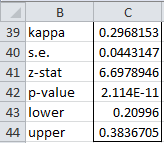
Figure 3 – Output from KAPPA function
Data Analysis Tool
Real Statistics Data Analysis Tool: The Interrater Reliability data analysis tool supplied in the Real Statistics Resource Pack can also be used to calculate Fleiss’s kappa. To calculate Fleiss’s kappa for Example 1 press Ctrl-m and choose the Interrater Reliability option from the Corr tab of the Multipage interface as shown in Figure 2 of Real Statistics Support for Cronbach’s Alpha.
If using the original interface, then select the Reliability option from the main menu and then the Interrater Reliability option from the dialog box that appears, as shown in Figure 3 of Real Statistics Support for Cronbach’s Alpha.
In either case, fill in the dialog box that appears (see Figure 7 of Cohen’s Kappa) by inserting B4:E15 in the Input Range, choosing the Fleiss’ kappa option, and clicking on the OK button. The output is shown in Figure 4.
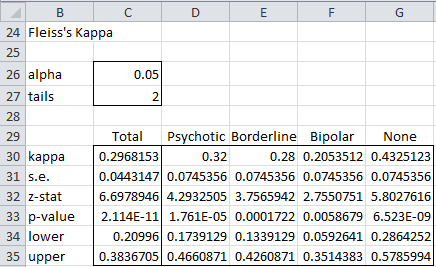
Figure 4 – Output from Fleiss’ Kappa analysis tool
Note that if you change the values for alpha (cell C26) and/or tails (cell C27), the output in Figure 4 will change automatically.
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
Links
References
Cardillo, G. (2009). Algorithm for Fleiss’s kappa, MATLAB
http://www.mathworks.com/matlabcentral/fileexchange/15426-fleisses-kappa/content/fleiss.m
Wikipedia (2013) Fleiss’ Kappa
https://en.wikipedia.org/wiki/Fleiss%27_kappa
Hi am needing some advise please.
I have a database of about 4000 plants and have information on each plant species from various sources. The information was obtained from about 30 different sources (raters). However many sources (raters) have only provided information for about 10% of the plant database. Hence I a lot of data on each plant but it is not from each rater. This implies that there are large gaps in data (but sufficient for me to conclude certain answers. The information has been captured in Excel. This also implies that there are large gaps between data in each column as well as in the rows. It has been recommended that I need to use Cohens Kappa (to test the agreement between raters), however in my reading I think that Fleiss Kappa is more suited. Can you advise on this. Also can you advise me of a website or youtube site that will explain how I set up a data set such as this correctly and what process and formula I use (preferably step by step guide).
Leslie,
Fleiss’s kappa can be used when you have many raters. It is not necessary that each rater rate each subject. The main criteria are that (1) each subject is rated by the same number of raters and (2) the rating are categorical (i.e. not ordered, such as in a Likert scale or with a decimal value). If the ratings use a Likert scale or a numerical value then the ICC might be a better way to go.
Before setting up your data, you need to be clear about what sort of data you have (i.e. number of raters, types of ratings, etc.).
Charles
Thank you for your wonderful explanation. According to my data set I am getting Z value as 17.8. Similarly each catogory Z value is above 25. What should I infer from this?
K= 0.437138277
var= 0.000593
se= 0.024351591
k/se =17.95111749
for each category
k1 0.722940023 0.301151045 0.270887021 0.154798991 0.392763376 0.497409713 0.401404805 0.473193742 0.296002606
var(k1) 0.000390278 0.0003871 0.000595739 0.001114339 0.000594559 0.000777897 0.000547207 0.000653159 0.000385771
se(k1) 0.019755455 0.01967485 0.02440776 0.033381712 0.024383589 0.027890808 0.023392452 0.025556984 0.019641059
z 36.59445027 15.30639563 11.09839766 4.637239447 16.10769338 17.83418051 17.15958671 18.51524193 15.0706028
Sreeja,
It is very difficult for me to answer your questions without some context. It would be better if you sent me an Excel file with your raw data and the analysis.
Charles
Sreeja,
Thanks for sending me the Excel spreadsheet. This makes everything much clearer.
I am also getting z values which are high, even higher than yours. The reason for the difference is that I am calculating a different value for the standard errors. The standard errors I am using come from the following paper.
Fleiss, J. L., J. C. M. Nee, and J. R. Landis. 1979. Large sample variance of kappa in the case of different sets of raters. Psychological Bulletin
What is the source of the standard errors that you are using?
Charles
Thank you. It’s very useful to understand the procedure of statistic.
In this page, There’s only explanation for ‘Within or between Appraisers’
Could you add some explanation for ‘Appraisers vs standard’ ?
It will be a lot help for me. Thank you
John,
This depends on your specific requirements. One approach is to Bland Altman. See the following webpage
Bland Altman
Charles
Thank you, Sir
Dear Sir.
This website helped me a lot in understanding statistics. Thank you.
Can you help me with the following?
I want to measure the interobserver agreement of three observers(raters) for evaluation of gastric tumors.
There are 445 subjects (n) and only two categories (whether benign or malignant).
It seems that Fleiss’ Kappa calculates the overall agreement of the three observers.
Can the Fleiss’ Kappa be used to calculate agreement between two observers?
For example, between observer 1 vs observer 2, observer 2 vs observer 3, and observer 3 vs observer 1? (I’m guessing not. Then should I use weighted Cohen’s kappa three times instead?)
Thank you.
M.C.
For pairwise agreement you can use Cohen’s Kappa (or Weighted Kappa).
Charles
Thank you for your explanation! I think I know why my previous attempts to calculate a kappa came out with nonsense, but I am not sure how to set up my data.
I have three raters, each watches two videos for each of 50 subjects. On each of the two videos, they score two different aspects on different scales. On video one, they score 6 items for aspect “A” on a 1-5 scale, and another for aspect “B” on a 0-14 scale. On the second video, they again score 6 items for aspect “C” on a 1-5 scale, and another for aspect “D” on a 0-12 scale. So I really have 14 evaluations per subject per rater, and two of them have a large number of possible scores (13-15). We were adding all the “A” items to get a score out of 30, and similarly all the “C” items to get a score out of 30, to only have 4 evaluations per subject per rater. I am afraid this is artificially lowering our inter-rater reliability, because it seems much less likely that any 2 raters will all agree on a score out of 15 or 30 than a score out of 5.
Do I need to run 14 kappa tests? And then, how do I get an overall inter-rater reliability rating from them? Or can the kappa test be set up to handle large numbers of possible scores? Should I be doing something totally different?
Hi Dr. Zaiontz,
Great tutorial! Straight to the point and instantly gratifying! I have a 22 raters evaluating 50 different scenarios. They then categorize the scenarios into 6 possible groups (nominal variable) according to what they believe is the correct category. I have calculated the interrater reliability using fleiss kappa according to your methods but I am also interested in overall rater reliability of all of the judges compared to a gold standard. The gold standard rating was done through the consensus of three independent raters using a tool. What test would you run to compare rater reliability to a gold standard?
thank you!
Hello Felix,
The Real Statistics website doesn’t cover this issue. The following paper may be useful in identifying an approach which meets your needs.
https://orbi.ulg.ac.be/bitstream/2268/39575/1/vanbelle-thesis-5-5-2009.pdf
Charles
Dear
Thank you for your explanation, I have a question
I’m following the formula for kj, but the values I get are not the same as your table, could help reviewing whether the values in your table are correct?
Thank you
Fernando,
I will look at your results if you send me an Excel file with your data and results. You can get my email address at Contact Us.
Charles
Buen dia;
es posible que me envien al archivo de excel practico .
You can download the examples files at
Examples Workbook
Charles
Dear Mr Zaiontz,
Thank you for excellent explanations of the Kappa statistics.
I have a few questions:
Regarding the z-value, it seems to always compare the result to K=zero. You say so on this web-site, and my statistical software has the same default which I cannot change. I find that a bit strange, it is not always good enough to be just a little better than tossing a coin. To introduce a new method you might want to prove it to be significantly better than fair Kappa ( which often is set at K=0.40, but I am aware that definitions vary between different authors).
If I want to compare Kappa values between two different sample populations, with the hypothesis that the Kappa of the test population is significant higher than Kappa of the reference population, I believe I have to calculate the z-score manually by subtracting the mean of the reference population from the test population and divide by SE of the test population. Then I calculate the p-value choosing a one-sided or two-sided test.
Do you agree on this, or are you of another opinion?
(I have a material with 3 observers/judges and 106 samples at two different departments with different training, and the size is chosen by a power calculation based on previous publications on the topic.)
Best regards,
Malin
Dear Malin,
I don’t know any tests to determine whether kappa is higher than some value p. I am not sure whether any simple approaches will work as the case for testing the correlation coefficient reveals. The approach for determining whether a correlation coefficient is significantly different from zero is quite different from that used to determine whether the correlation coefficient exceeds some value. This is because in the first case, you can assume a normal distribution (at least under the null hypothesis) and use a t distribution, while in the second case you can’t assume a normal or t distribution.
I also don’t know any methods for comparing two values of kappa based on two different measurements. The approach that you are considering may be appropriate if you can figure out what a suitable pooled s.e. should be. Again we can look at the correlation coefficient where the pooled s.e. is not so obvious.
I have found the following research paper, which may be useful, although I have not read it myself.
McKenzie DP. Mackinnon AJ. Peladeau N. Onghena P. Bruce PC. Clarke DM. Harrigan S. McGorry PD. Comparing correlated kappas by resampling: is one level of agreement significantly different from another?. Journal of Psychiatric Research. 30(6):483-92, 1996 Nov-Dec.
Charles
Hi Charles
Thank you for a very useful website.
I followed the instructions to calculate Fleiss Kappa, including s.s. and CIs, but I run into trouble with the p-value. My Excel does not seem to like the command with NORMDIST, and I tried following the steps to install your software but no luck so far. Therefore, is there a formula to calculate the p-value? Or how can I ‘unpack’ the command you suggested above? Is there a way to ‘tell’ Excel what to do in a different way?
Many thanks
Paula,
The website uses the function NORMSDIST not NORMDIST. NORMSDIST(x) is equivalent to NORM.S.DIST(x,TRUE) on newer versions of Excel (although the older version still works).
Charles
Thank you for your reply, Charles.
And thank you for picking up my mistake – all sorted now! My p-value came up with 0 – by reading the previous comments on here, I’m guessing that this is acceptable. With regards to reporting the inter-rater reliability, would you say that it is better to report Kappa and CIs, or should I report the p-value as well? Sorry, I’m quite new to this.
Many thanks again.
Paula
Hi,
first of all i want to thank you for the article.
I have a question concerning Fleiss’ Kappa. You wrote: “[…] in the case of Fleiss’ kappa, there may be many more than m judges and not every judge needs to evaluate each subject; what is important is that each subject is evaluated m times.”
So my problem is this: we have around n=350 subjects, k=7 categories and m=6 judges. My problem is as follows: (a) not every judge evaluated each subject and (b) every judge can evaluate each subjekt into 2 categories (it’s a pre-evaluation; after the pre-evaluation we want to meet and discuss our results and finalize our categorization).
Is there any way i can still work with Fleiss’ Kappa? Is in this way m=12, because each judge can evaluate each (problematic) subject into 2 categories?
Thanks in advance!
One remark concerning (b): a subject can be evaluated into 2 categories, but doesn’t have to.
David,
I don’t completely understand the scenario. You say that there are 7 categories but you also say there are 2 categories. Which is it? Perhaps it would be helpful to have an example with some data.
Charles
I got it .. thank you very much .. I will read it and study it … if there any question I will send it to you .. thank you very much again.
Thank you very much … I need help
what do you recommend to carry out a content validity index
Sorry, but I haven’t addressed this topic on the website yet. The following document may be useful:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.460.9380&rep=rep1&type=pdf
Charles
Thank you very much
but I failed to open the link or download the file.. can you please send the pdf as attachment to my e-mail .. elsayedamr@yahoo.com
Just enter the link on your browser and you should be able to access it. It is not from my site, but from another site on the Internet.
Charles
I failed again … If you please what is the title of the paper and I will manage getting it.
The title of the paper is A Quantitative Approach to Content Validity by C. H. Lawshe of Purdue University.
Charles
Hi Charles.
Thanks for the wonderful tools and explanations. I am trying to use the Real statistics free download to perform a Fleiss’ kappa analysis and running into some issues. When I copy the sample data from Figure 1 into Excel and use the Fleiss’s kappa option under the reliability procedures menu the output field comes back with every cell filled in #N/A. Can you suggest some solutions to this issue?
Thanks,
Amanda
Amanda,
Perhaps that is because you also used column A in the Input Range. The input should not include this column.
Charles
Sir,
Can Cohen’s Kappa or Fleiss Kappa be use for any other statistical agreement data. Or the ‘rater’ in here only for human respondents? Can the ‘rater’ also means previous study?
Thank you.
A rater doesn’t have to be human. It can be a previous study.
Charles
Thank you so much Charles!!
Dear Dr. Leinder
Thank you very much for the article. I am working on biotic indices. I want to see the agreement of the indices to evaluate the ecological status. The indices are classified into 5 categories (Bad, poor, Moderate, Good and high). I have about 610 samples.
I would like to know which test to apply. Kappa or ICC.
The categories used are i.e Bad=1, Poor= 2 Moderate= 3 etc.
In general, how do i arrange the data. I have arranged the data as following
Example 1
Stn BI1 BI2 BI3 BI4 BI6 BI 7 BI8
Stn1 1 2 3 2 3 4 3 3
Stn 2 1 2 4 2 3 4 3 4
Example 2
Bad Poor Mod Good High
Stn 1 1 2 4 1 0
Stn 2 1 2 2 3 0
Which is the correct method? If example 2 is correct is there are easy method to it. I did few samples manually, but 610 samples is too much.
Thanks!
Hi,
Looking at the equation to compute kappa for the jth category, I can see that the denominator includes the number of subjects assigned to that category. I would like to know your opinion about the following conclusions I loosely deduce from this equation:
Categories that are bigger in the data and get a higher number of subjects assigned to them, might probably have higher values of kappa than those much smaller categories (with very few subjects belonging to them) just due to the fact that they are bigger (i.e., kappa is biased towards size of categories in the data itself)
Additionally, can you suggest any other inter-rater agreement measure that’s less sensitive to categories size (assuming 3 annotators)?
As I said in my previous comment, I am not certain whether Fleiss’ Kappa is indeed sensitive to category size. In any case, the bigger issue is whether you have ordered data or categorical data. In the first case, Fleiss’ kappa is a reasonable choice. In the second case, the intraclass correlation is a reasonable choice.
Charles
Hi,
I haven’t had time to really look at the formulas to see whether your observation is true or not, but I noted that for Example 1, the exact opposite is true. The two categories with the highest number of subjects have the lowest kappa values.
Charles
Hi,
Thanks for the great tutorial and tool. I am working with thousands of samples, 2 categories (yes and no) and 3 annotators. When I computed Fleiss Kappa using the Excel tool, the results I get show that the per-category kappa values are equal for both categories (e.g., “yes” kappa = “no” kappa = 0.47). I repeated that computation over a completely different set of samples but with same setting (two categories, 3 annotators) and I also get the same result (i.e., per-category kappa values are equal across the categories). Is this normal? Could you please explain why this is happening?
Just to add more context, in both sets of data, I realized that the standard deviation of annotations counts is equal across the categories, but the mean is different.
If you send me an Excel file with your data and results, I will try to figure out what is happening. You can find my email address at Contact Us.
Charles
Just did. Thanks for the great help!
Maram,
Since you only have two categories, the values for the two categories will be equal. This won’t be the case with more than two categories.
Charles
hello.. i need help..to figure out how..to get fleiss kappa value..if I have 5 expert valuation.. and the scale use of the item..is 1 to 10.
example
item expert 1 expert 2 expert 3
1 8 9 10
2 8 8 8
3 9 9 9
4 10 10 10
.
.
.
81 9 9 9
tq
I don’t recommend using Fleiss’ kappa with ordinal data. Better to use Intraclass Correlation Coefficient. See the webpage
Intraclass Correlation Coefficient
Charles
Sir
I have a question in the case of reference value known.
How to deal with the data matrix if we need to evaluate overall Fleiss Kappa when the reference value is known for each sample? Just assume we have already known the actual kind of illness for these 12 patients, now 6 judges give their judement to each patient.
This situation is actually kind of Attribute MSA and MINITAB gives its answers, but I deducted several times with the formulas and was not able to give the exact answer in this case. However, the deduction for the case of reference value unknown is the same as MINITAB’s (like your case here).
Appreciate your reply.
Thanks.
Vincent,
I believe that you are looking for an implementation of Attribute Gage R&R. I plan to look into doing this in one of the next releases of the software.
Charles
Our P value in the row is as mentioned below:
m 3
n 1000
pa 0.4815
pe 0.253083444
kappa 0.305812683
s.e 0.010177511
z 30.04788446
p-value 0.0000
alpha 0.05
lower 0.285865127
upper 0.325760238
The P value in the column is as indicated below:
q 0.074 0.206333333 0.334333333 0.290333333 0.094666667
b 0.068524 0.163759889 0.222554556 0.206039889 0.085704889
k 0.708131458 0.395456356 0.167245385 0.221833528 0.377709556
s.e 0.018257419 0.018257419 0.018257419 0.018257419 0.018257419
z 38.7859573 21.66003666 9.160406974 12.15032275 20.68800442
p 0.00000 0.00000 0.00000 0.00000 0.00000
question:
Is there any issue if our P value is a null element?
Please reply as soon as possible.
Thanks…
The p-value can be zero (probably a very small number). I have not checked your calculations, but you can get a zero answer. You can check your answer by using Real Statistics’ KAPPA function.
Charles
Thanks a lot, sir. I have sent u an e-mail with the excel sheets for calculation. Can you please have a look and give the solution?
Hi! Thanks for this page.
I have two questions:
1. I would like to compare Fleiss kappa values, for example, 0.43 (95% CI 0.40, 0.46) and 0.53 (0.43, 0.56). The confidence intervals overlap – is this enough to say that the two Fleiss kappa values are not statistically significantly different from each other? I have read that this may not be the case, link: http://www.cscu.cornell.edu/news/statnews/stnews73.pdf
2. I often see % agreement reported in articles when using Cohens kappa (2 observers). Is this something that is done with Fleiss kappa? If so, how is it calculated (is it number of cases where all observers rate the same/total number of cases)? I have noticed that the % agreement I obtain when calculating Light’s Kappa instead of Fleiss kappa is always higher…
Trina,
1. The article you referenced states that just because the confidence intervals overlap doesn’t mean that the two Fleiss kappa values are not statistically significantly different from each other.
Here is a web reference regarding comparing two Fleiss kappa values. Perhaps it is useful to you.
https://www.researchgate.net/post/Can_anyone_assist_with_Fleiss_kappa_values_comparison
2. You can get information about Cohen’s kappa at the webpage
Cohen’s Kappa
Charles
Hi Charles,
I am getting unusual results following the guide when the raters are at almost perfect agreement.
I have 9 cases, each with 4 categorical ratings by 8 raters.
Cases\Ratings 1 2 3 4
1 0 0 0 8
2 0 0 0 8
3 0 0 0 8
4 0 1 0 7
5 0 0 0 8
6 0 0 0 8
7 0 0 0 8
8 0 0 0 8
9 0 0 0 8
The kappa is -0.014 and the p-value is 1.177. Will you be able to advise as I am uncertain what’s going on?
Thanks!
Cheers,
BC
BC,
Unfortunately, many of these measures give strange results in the extreme cases. The best way to look at these situations is that when you have almost perfect agreement you don’t really need to use Fleiss’s Kappa. Not very satisfying answer, but it is true.
Charles
Thanks Charles for the clarification. It’s a good answer to clarify my doubts as I was sieving through all my equations in excel and found no errors.
In a scenario like this, will analysing by ICC for inter-rater reliability (multiple rater) be better? What’s your recommendation?
You would use the ICC with rankings that are quantitative. Fleiss’s kappa is used with categorical data. In situations like this you would simply note that there is obvious agreement and not use any of the usual measures.
Charles
Thanks Charles for the further explanation, much appreciated!
Thank you for this page. It has helped but I am now wondering if Fleiss’ kappa is the correct statistical test for our purposes. I have running a test-retest reliability study on a biological response to a stimuli. There are 4 response pattern categories. Six subjects underwent 4 repeated tests. We want to know if the same subject will attain the same test response to the same stimuli under the same conditions.
Currently, my subjects are the rows, and the response pattern categories are the columns, with each test week as the ‘rater’.
In your opinion, should we use Fleiss’ kappa or ICC?
Thanks for this page, I am a stats novice, so am very grateful for having a clear ‘recipe’ to follow.
Catherine
Catherine,
If the data is ordered (especially with values such as 41.7, etc.) ICC will take the order into account. If the data is categorical (no order) then Fleiss’ is the approach to use.
Charles
Data is categorical so we will stick with Fleiss’ kappa. Thank you so much for your assistance and your prompt reply.
Catherine
Ok Charles thank you very much.
Dear Charles,
i computed standard error and confidence interval according to your instructions. May I ask you where you found the formula for the confidence interval? Or did you come up with it on your own?
Thanks a lot for providing this information!
Cheers,
Henk
Henk,
I think I got it from the following paper
http://www.bwgriffin.com/gsu/courses/edur9131/content/Banerjee-BeyondKappa.pdf
Charles
Thank you very much for your reply, Charles.
I am not quite sure what I need to use, though.
I will give an example to make the understanding of the case easier.
I have 10 criteria that are hypothesised to be important in establishing a diagnosis. 30 experts will rate the importance of each criterion on a likert scale from 1 (not important) to 5 (very important).
What I want to know, is what statistic (besides CV) I can use to evaluate the agreement between all the 30 experts on each single criterion.
Many thanks!
Mattia,
If you want to rate the agreement between all 30 experts across all 10 criteria then you could use the intraclass coefficient (ICC) as described on the webpage Intraclass Coefficient
For your situation instead of Judges A, B, C and D in Example 1, you would have the the 30 experts (these are the columns) and instead of 8 wines would have the 10 criteria. The table would be filled with ratings 1 to 5.
If instead you want to evaluate agreement one criterion at a time, then I don’t have any specific advice to offer. I have come across the following paper which may be helpful. I have only read the Abstract and I am not sure about the paper’s quality or applicability to your problem.
http://www.amsciepub.com/doi/abs/10.2466/pr0.1998.82.3c.1321?journalCode=pr0
Charles
Dear Charles,
I am trying to identify the appropriate measure to use for my inter-rater agreement test. After much research, I believe it may be the Fleiss’ kappa measure, but am not sure as I have not been able to locate literature which suggests it can be used in my specific case presented below.
I have developed a multiple choice test with 58 items based on teaching scenarios and what teachers might do in a particular classroom situation. Then I had 5 expert teachers take the test so that I could attain an agreed upon answer key. Now I want to run a test which provides me with a value which justifies the answer key as having substantial agreement (0.61 – 0.80), perfect agreement (0.81 – 1.00), etc.
I cannot seem to find literature specific to obtaining inter-rater agreement of an answer key to a multiple choice test. In short, my question is what index is appropriate to test the level of agreement for this situation and what research is there to back that decision?
Any advice would be greatly appreciated.
David
Hi Charles,
I would also like to clarify that the 58 multiple choice questions each have three choices, which only 1 is correct. These three choices are nominal or categorical in nature.
David,
Generally in situations where it is clear what is the correct answers are to a multiple choice test, you might run Cronbach’s alpha to check for the internal consistency of the test, but it seems that you are testing for agreement among experts as to what the correct answers are and the categories are nominal. This seems to be a good fit for Fleiss’ kappa.
Charles
Thank you Charles.
I have forged ahead on your recommendation. The kappa value that was returned using the program provided on the domain https://mlnl.net/jg/software/ira/ (Geertzen, 2012)
was 0.77, which according to Fleiss (2003) represents excellent agreement beyond chance. Would you agree with this assessment of the returned k value? Have you seen the on-line program I refer to above?
Thank you, David
David,
I am not familiar with the program you referenced.
You could use the Fleiss’ Kappa option the Real Statistics Reliability data analysis tool to calculate Fleiss’ kappa.
Charles
Hi Charles,
I’m working on a content analysis project and would like to compute a Fleiss’ kappa but I’m not sure how to organize the data. There are five coders, and they’ve coded 20 Tweets for content in 19 categories. Coding values are nominal categories, one through three.
Can you toss me a bone?
Thanks,
Rob
Robert,
Since the 5 raters are rating 20 Tweets, the Tweets are the rows and the sum of numbers in each row is 5.
Since there are 3 nominal ratings 1 through 3, there are 3 columns. The cell in the ith row and jth column contains the number of the raters who have given the ith Tweet a rating of j.
The problem is that you have 19 such ratings, one for each category (if I have understood the problem correctly), which means that you have to calculate Fleiss’ Kappa 19 times, once per category. There may be a multivariate Fleiss’ Kappa that does the job you want, but I am not familiar with such a measure.
If instead you
You do indeed understand the problem correctly. Currently I’m organizing the data manually — converting raw scores into categorical agreement figures (0-5-0, 1-4-0, and so on). It’ll take a while but I’ll give it a shot. (Isn’t there some way to get Excel to do this sort of computation so I can avoid human error?)
Robert,
There may be some easier way of doing this reorganization of the data in Excel, but I’d have to see how the data is formatted to really provide a good answer. But by the time I figured it out you will have probably reorganized the data manually. Sorry about that.
Charles
Charles,
Thanks for your mindful relies. Let me run one more thing past your eyes and then I’ll stop.
My five coders coded several categories for variables we didn’t expect to see in very many of the 20 tweets, so all of the coders made substantially the same decisions of “not present” (or a code of “2”). Nearly every tweet was coded the same way by every coder, so the frequency grid looks like this for 15 of the Tweets:
0-5-0
There are five cases of a coder that coded “present” (or a “1”), so five of the data lines look like this:
1-4-0
What puzzles me is that the reported kappa is -0.053, and I don’t know how to interpret this result. In another category there is a single disagreement of this type, and the result is a kappa of -0.010.
I’ve computed kappa for the data sets using two templates and I get the same thing so I think I’m computing it correctly. What does a kappa of -0.010 mean?
Thanks in advance for your help!
Rob
When most of the responses are the same kappa will sometimes give strange results. To me it is a deficiency in the kappa statistic, but if there is for example there is only a single disagreement, there really isn’t much reason to use kappa.
Charles
Hi Charles,
Need some advice. I don’t know how to organize data so I can compute a Fleiss’ kappa. Here’s what I’ve got:
Five coders have coded 20 Tweets for content in 19 categories with a data range of 3 (1=present, 2=not present, 3=can’t tell). Right now the data exist in an Excel workbook with each coder’s data on separate sheets. I get this much: k=categories (there are three), and m=number of judges (there are five). What is n? The number of Tweets? The number of content categories in the Tweets? How do I convert the five spreadsheets into a grid that expresses agreements in each category?
I can’t get my mind around it. Any tip you might have would be very much appreciated!
Rob
Hi,
In my study, each subject is to be rated on a nominal scale from 1 to 5. If each subject was rated by 2 raters, but the 2 raters were drawn from a pool of 6 raters, I can apply Fleiss’s kappa in assessing the inter-rater reliability, right? Is there any requirement on the minimum times that each rater participated, i.e. should I exclude the rater that rated, say extremely, one subject only?
Moreover, if each subject was rated by different number of raters, what method can I use instead? I find that you have mentioned an extension of Fleiss’s kappa as linked, http://conservancy.umn.edu/bitstream/99941/1/v03n4p537.pdf, but seems that it can be applied for dichotomous variable only and thus not suitable for me.
Would Krippendorff’s alpha be appropriate? But I am not sure if I can treat those raters that do not rate the subject as missing data, since this type of “missing” is not random in nature.
Thanks a lot in advanced.
Lam
Lam,
If I understand the problem correctly, you could use the intraclass correlation (ICC), but this measurement requires that all the subjects have the same number of raters. If the number of raters is not too unbalanced and the samllest number of raters is not too small, perhaps you can randomly eliminate some ratings to create a balanced model (alternatively you might be able to use some multiple imputation approach).
I am not familiar with Krippendorff’s alpha, but I do believe there are techniques for handling missing data.
Charles
Thanks Charles,
For my own experience, I used to use ICC for continuous variables and kappa for discrete/ nominal variables. As the data this time is in nominal scale, may I confirm if ICC can still be applied?
In addition, I could now probably fixed the number of raters to be 3 each time (not the same raters). Would you suggest whether ICC or Fleiss’s kappa be more appropriate?
Sorry that I have got so many questions. Thanks again!
Lam
Lam,
To use ICC the data doesn’t need to be continuous, but it does need to be ordinal. E.g. you could use it with a Likert scale (say 1 to 7). If the data has no order then you shouldn’t use ICC. Fleiss’ kappa is only used with nominal data and order is not taken into account. If your data is unordered then you should use Fleiss’ kappa. If it is ordered you should use ICC.
Charles
It is absolutely correct.
May you please give me an specific reference for such an statement. I do agree with what you have mentioned, however, I do not have access to the reference of your statement. I did search for “Colin” but I did not find anything useful!
Thanks.
…[a] specific…*
…such [a] statement…*
Hi,
1. I have a set of data with 38 raters rating the content of videos with regards to 8 items* that are all based on the same ordinal scale (very good, good, adequate, insufficient). My results are puzzling for me, because when I’m calculating Fleiss’ Kappa for each item individually (matrix: 1*38) the coefficients (mostly highly significant) are all smaller than when I’m calculating Kappa for all items together (matrix: 8*38). Shouldn’t the overall coefficient (K=0,31) be within the range of individual coefficients (K=-0,13 to 0,28)?
2. Dr. Leidner wrote above that “There are no “criteria” for how to interpret Kappa – you can compare inter-annotator agreement, but to judge its absolute value depends on the task’s inherent difficulty. There are some “guidelines” in the literature, but they are bogus.” My problem is that I have to interpret the effect sizes and I have no idea if my effects are strong or weak. From the info I gave you, can you say if my coefficients are high enough to speak of a good rater agreement? And do you know of any helpful literature on this topic.
Thanks for your help,
Philipp
*Their task is to assess the driving competency of driving license applicants that we filmed during a simulated test drive.
Sorry Charles, I didnt notice that your email was avaiable. thanks
Raphaela,
I just checked the spreadsheets you sent me and see that the problem is that the sum of the scores in each row are not the same. If these sums are not the same you will see errors in all the cells.
Charles
Good morning,
can I dowaload again RealStat to calculate Fleiss´Kappa? ( calculate the agreement among multiple judges and multiple variables)? please let me know. thank you
Yes. The new version of this function is now available. You can also use the new Reliability data analysis tool.
Charles
Charles, I got a probelm. I have a matriz 0-1 , 11 variables and 15 judges. I applied Fleiss Kappa (Reability data analysis tool) and it results alpha 0,05 and the table below have errors. any idea? thx
Raphaela,
Without seeing the spreadsheet I can’t tell what went wrong. The most common problem is that the input data is not formatted correctly. If you send me the spreadsheet I will be able to help you better.
Charles
I really appreciate !! could you please send me email and I will reply with the spreadsheet attached. Thankss
Raphaela,
My email address is given on the Contact Us page (see Main Menu)
Charles
ok. Charles, Thank you 🙂
Professor, How I calculate Fleiss´Kappa with Real Statistics? click in data anslyse tool and ?
thx
Raphaela
Raphaela,
Currently you need to use the KAPPA function as described on the referenced webpage.
Tomorrow I will issue a new release of the Real Statistics Resource Pack. This release has an improved version of the KAPPA function. In addition there will be a new Reliability data analysis tool which will calculate Fleiss’s Kappa.
Charles
OK. Thank you so much.
So, I dowload Real Statistics again or only the addition?
Raphaela,
There is no addition, only a full release. I expect to issue the new release later today.
Charles
Hi,
In Figure 2, B17 and B18 rows should be interchanged.
Have a nice day.
Hi Ali,
Great catch. I have now corrected Figure 2 as you have suggested. Thanks for identifying this error.
Charles
Hello,
I am interested in determining the degree of agreement between 4 raters on an observation instrument that involves a rating system of 1 – 4 (levels of proficiency with a target attribute). I believe that Fleiss would be the appropriate measure in this case. Is this correct?
Thanks,
Stacy
Stacy,
Yes, Fleiss’s kappa can be used for this purposes.
Charles
Dear Dr. Leinder,
I want to test the reliability of a newly constructed diagnostic interview. Therefore, raters watched videos of diagnosticians interviewing patients and answered for most of the items on a one-to-five likert scale and for some on a yes/no-basis (as the interviewers did). The agreement between the raters, measured by Fleiss Kappa, is thought to be my estimation of the interrater-reliability. Does that sound right so far?
The problem is that some of the items are multiple choice items. Is it still possible to use Fleiss kappa? It seems the statsitic programs can’t handle that… If not, could you give me a hint what kind of calculation I could use instead? Intraclass-correlations (some items are based on categorial scales…)?
And one last (general) question: Is there a relation between interrater reliability and criteriums validity – otherwise than reliability as a condition for validity? My prof is always talking about a paper called “study into criterium validity…” (based on the data I described). I didn’t challenge him so far cause I’m not sure I’m right…
Thanks so much in advance.
Best regards
Kathi
Dear Kathi,
You have addressed your question to Dr. Leinder. Since am not Dr. Leinder perhaps this comment was not intended for me.
Please give me an idea of some of the questions, especially the multiple choice questions.
I don’t know which type of relationship your professor was talking about between interrater reliability and criterion validity.
Charles
Hi,
I am comparing the reliability of 3 different imaging tests for classification of a condition that has 10 different classes. There are 4 raters and 123 cases. Each reader reviews each case 3 separate times, each time using one of the three different models. Each model will have a Fleiss’ kappa. The reliability of the models can then be assessed comparing the three Fleiss’ kappas?
There is no good gold standard for the condition.
thanks
yvonne
Hi Yvonne,
If I understand your situation correctly, Fleiss’s Kappa with measure the degree to which the 4 raters agree on their classification of each imaging test. If your goal is to select which of the three imaging tests provides the most agreement between the raters then it may be worthwhile comparing the kappa measurements (you still wouldn’t know whether any differences are statistically significant). I wouldn’t necessarily call this a measure of the reliability of the models.
Charles
Hi,
Thanks so much for the timely response!
I am attempting to assess the reliability of the assessment tool, not the observers (nurses) though I understand that I may need to assess the observers seperately.
What I understand you to say that I can rate the symptoms as y/n and the rated questions (1 through 9) as likert style. In doing so, Cronbach’s Alpa is the best tool to test all questions together given the goal is to test the tool.
Thanks for your reply,
greatly appreciated.
dove.
Hi;
So greatful for your web-site and resources. If I might test my idea:
I am attempting to test the reliability of an assessment tool.
The tool has nine (9) questions with responses range from 0-3 and
Three (3) fields where the evaluator can select any combination of symptoms or select none of the symptoms from items on the symptom check list (8-10 items available to choose).
As I understand it, I should seperate out the responses into two data fields and measure the reliability of the 9 questions using ICC (IntraClass Correlation) formula and test the second half (reported symptoms) using the Fleiss Kappa analysis formula.
Is this correct?
I greatly appreciate your resonse.
Hi,
It really depends on what you are trying to measure. E.g. you could use Cronbach’s alpha for the nine questions to determine the internal consistency of the questions. Are you evaluating the reliability of the questionnaire or the degree of agreement between the evaluators (I assume these are the nurses)?
For the symptoms you could treat each symptom as a True/False question (True = patient assessed to have that symptom, False = assessed not to have that symptom). The analysis can them proceed as for the first group of questions (with my same question to you, namely what are you really trying to assess?
Charles
i did the observation for a process in operating room, i have 2 sets of observers: assigned observers and participant observers:. the results for 14 categories were as follows:
1 2
1 230 250
2 259 260
3 260 260
4 249 251
5 260 260
6 238 256
7 250 252
8 217 229
9 212 218
10 258 256
11 189 197
12 245 248
13 245 248
14 254 258
15 260 260
and the results of Fleiss’s Kappa was:
Fleiss Kappa for 480 raters = 0.0402 SE = 0.0008
95%CI = 0.0387 to 0.0417.
so, could you please guide whats mean of the results, is there agreements between 2 observers ??
Mohammad,
There is no clear cut agreement as to what is a good enough value for Fleiss’s kappa, but a value of 0.0402 is quite low, indicating that there is not much agreement.
You mention in your email that there are 14 categories and 480 raters, but I don’t understand the results for the 14 categories you listed, starting with the fact that there are 15 categories in your list.
Charles
Dear Sir,
I’m having some troubles in calculating the kappa for my sample. I have 189 patients, 3 evaluators and 2 possible diagnoses but I am not able to apply the formulas you suggest, maybe because of the different translations of the formulas themselves (I’m Italian). I am really having many problems and I need this kappa for my final project at university so I was wondering if you could help me or if you have an excel spreadsheet which I can put my numbers in, please. Thank you very much
Dear Alessandra,
If I am understanding the problem correctly, your input should be similar to Figure 1 in the referenced webpage with two data columns (one for each diagnosis) and 189 rows (one for each patient). The sum of the values in each row should be 3 (for the 3 evaluators).
You can get a copy of the worksheet I used to create Figure 1 by downloading the Worksheet Examples file at https://real-statistics.com/free-download/real-statistics-examples-workbook/. Once you have this you can modify it to fit your specific problem.
Charles
Dear Sir,
Could the number of judges (m) for every subject, different?
for example:
test subject #1 is evaluate by 5 psychologist
test subject #2 is evaluate by 6 Psychologist
…
…
and so on.
Dear Nara,
As far as I am aware Fleiss’s kappa requires the same number of judges for every subject. There are extensions where this requirement is relaxed. See for example http://conservancy.umn.edu/bitstream/99941/1/v03n4p537.pdf.
Charles
is it possible to use Fleiss Kappa for 45 respondents rating 5 different interventions each on a total of ten??
Sure. This should work. Just try it.
Charles
Hi, I am having problems with the excel whenever I write the “,”
So instead I am writing “;” but I don’t think it is the same since I get to a point the numeric result becomes #VALUE!
Please help. Thanks
Hi Eloi,
I am not sure what is happening, but I know that for languages that use a comma as the decimal point, Excel uses a semi-colon instead of a comma to separate arguments in a function. This may be what is causing the problem you have identified. In this case, depending on what you are trying to do you may need to use a semi-colon instead of a comma. Alternatively you can change the number/currency defaults in Windows (via the Control Panel) so that a period and not a comma is used as the decimal point.
Charles
Hi
I should correct that the no. of subjects is what I need to calculate. 4 is what we’re currecntly planning with but this might not be enough to prove a rater agreement (Fleiss’ Kappa) of .7 or higher on a .95 confidence level.
Thanks
Philipp
Hi
Please excuse if I’m not using the right terms in English.
For a study that I’m conducting I need to calculate the minimum sample size for Fleiss’ Kappa for the following parameters:
no. of raters: 50
no. of subjects: 4
Fleiss’ Kappa >= .7
alpha = .05
power = .80
Is there a formular for this like for other statistical measures? Does the standard error decrease with the no. of raters and with the no. of subjects? I’ve been researching the web on this for a while but cannot find the information I need.
Thanks for your help,
Philipp
Philipp,
I’m afraid that I don’t have any information about sample size requirements for Fleiss’s kappa. I have come across websites re sample size requirements for Cohen’s kappa and ICC, including the following, but not for Fleiss’s kappa.
http://www.ncbi.nlm.nih.gov/pubmed/12111881
http://ptjournal.apta.org/content/85/3/257.full
Charles