Basic Concepts
Factor analysis doesn’t make sense when there is either too much or too little correlation between the variables. When reducing the number of dimensions we are leveraging the inter-correlations. E.g. if we believe that three variables are correlated to some hidden factor, then these three variables will be correlated to each other. You can test the significance of the correlations, but with such a large sample size, even small correlations will be significant, and so a rule of thumb is to consider eliminating any variable which has many correlations less than 0.3.
Reproduced Correlation Matrix
We can calculate the Reproduced Correlation Matrix, which is the correlation matrix of the reduced loading factors matrix.

Figure 1 – Reproduced Correlation Matrix
Referring to Figure 2 of Determining the Number of Factors, the reproduced correlation in Figure 1 is calculated by the array formula
=MMULT(B44:E52,TRANSPOSE(B44:E52))
By comparing the reproduced correlation matrix in Figure 1 to the correlation matrix in Figure 1 of Factor Extraction, we can get an indication of how good the reduced model is. This is what we will do next.
Error Testing
We can also look at the error terms, which as we observed previously, are given by the formula
![]()
Our expectation is that cov(ei, ej) ≈ cov(εi, εj) = 0 for all i ≠ j. If too many of these covariances are large (say > .05) then this would be an indication that our model is not as good as we would like.
The error matrix, i.e. R – LLT, for Example 1 of Factor Extraction is calculated by the array formula,
=B6:J14-MMULT(B44:E52,TRANSPOSE(B44:E52))
(referring to cells shown in Figure 1 of Factor Extraction and Figure 2 of Determining the Number of Factors) and is shown in Figure 2.
Note that the main diagonal of this table consists of the specific variances (see Figure 3 of Determining the Number of Factors), as we should expect. There are quite a few entries off the diagonal that look to be significantly different from zero. This should cause us some concern, perhaps indicating that our sample is too small. One other thing worth noting is that the same error matrix will be produced if we use the original loading factors (from Figure 2 of Determining the Number of Factors) or the loading factors after Varimax rotation (Figure 1 of Rotation).

Figure 2 – Error Matrix
Bartlett’s Test
Note too that if overall the variables don’t correlate, signifying that the variables are independent of one another (and so there aren’t related clusters that will correlate with a hidden factor), then the correlation matrix would be approximately an identity matrix. We can test (called Bartlett’s Test) whether a population correlation matrix is approximately an identity matrix using Box’s test.
For Example 1 of Factor Extraction, we get the results shown in Figure 3.

Figure 3 – Bartlett’s Test
We first fill in the range L5:M6. Here cell L5 points to the upper left corner of the correlation matrix (i.e. cell B6 of Figure 1 of Factor Extraction). Cell L6 points to a 9 × 9 identity matrix. 120 in cells M5 and M6 refers to the sample size. We next highlight the 5 × 1 range M8:M12, enter the array formula BOX(L5:M6), and then press Ctrl-Shft-Enter.
Since p-value < α = .001, we conclude there is a significant difference between the correlation matrix and the identity matrix.
Partial Correlation Matrix
Of course, even if Bartlett’s test shows that the correlation matrix isn’t approximately an identity matrix, especially with a large number of variables and a large sample, it is possible for there to be some variables that don’t correlate very well with other variables. We can use the Partial Correlation Matrix and the Kaiser-Meyer-Olkin (KMO) measure of sample adequacy (MSA) for this purpose, described as follows.
It is not desirable to have two variables that share variance with each other but not with other variables. As described in Multiple Correlation this can be measured by the partial correlation between these two variables.
Calculating partial correlation matrix
To calculate the partial correlation matrix for Example 1 of Factor Extraction, first, we find the inverse of the correlation matrix, as shown in Figure 4.

Figure 4 – Inverse of the correlation matrix
Range B6:J14 is a copy of the correlation matrix from Figure 1 of Factor Extraction (onto a different worksheet). Range B20:J28 is the inverse, as calculated by =MINVERSE(B6:J14). We have also shown the square root of the diagonal of this matrix in range L20:L28 as calculated by =SQRT(DIAG(B20:J28)), using the Real Statistics DIAG array function. The partial correlation matrix is now shown in range B33:J41 of Figure 5.

Figure 5 – Partial correlation matrix
The partial correlation between variables xi and xj where i ≠ j, keeping all the other variables constant, is given by the formula
![]()
where Z = the list of variables x1, …, xk excluding xi and xj, and the inverse of the correlation matrix is R-1 = [pij]. Thus the partial correlation matrix shown in Figure 5 can be calculated using the array formula
=-B20:J28/MMULT(L20:L28,TRANSPOSE(L20:L28))
Since this formula results in a matrix whose main diagonal consists of minus ones, we use the slightly modified form to keep the main diagonal all ones:
=-B20:J28/MMULT(L20:L28,TRANSPOSE(L20:L28))+2*IDENTITY()
Kaiser-Keyer-Olkin (KMO)
The Kaiser-Meyer-Olkin (KMO) measure of sample adequacy (MSA) for variable xj is given by the formula
![]()
where the correlation matrix is R = [rij] and the partial covariance matrix is U = [uij]. The overall KMO measure of sample adequacy is given by the above formula taken over all combinations and i ≠ j.
KMO takes values between 0 and 1. A value near 0 indicates that the sum of the partial correlations is large compared to the sum of the correlations. This indicates that the correlations are widespread and so are not clustering among a few variables, which would indicate a problem for factor analysis. On the contrary, a value near 1 indicates a good fit for factor analysis.
For Example 1 of Factor Extraction, values of KMO are given in Figure 6.

Figure 6 – KMO measures of sample adequacy
E.g. the KMO measure of adequacy for Entertainment, KMO2 (cell C46) is calculated by the formula =C15/(C15+C42) where C15 contains the formula =SUMSQ(C6:C14)-1 (here one is subtracted since we are only interested in the correlations with other variables and not with Entertainment with itself) and C42 contains the formula =SUMSQ(C33:C41)-1. Similarly, the overall KMO (cell K46) is calculated by the formula =K15/(K15+K42), where K15 contains the formula =SUM(B415:J415) and K42 contains the formula =SUM(B42:J42).
Interpreting the KMO
The general rules for interpreting the KMO measures are given in the following table
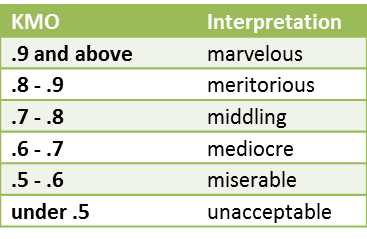
Figure 7 – Interpretations of KMO measure
As can be seen from Figure 6, the Expectation, Expertise, and Friendly variables all have KMO measures less than .5, and so are good candidates for removal. Such variables should be removed one at a time and the KMO measure recalculated since these measures may change significantly after the removal of a variable.
It should be noted that the matrix all of whose non-diagonal entries are equal to the corresponding entries in the Partial Correlation Matrix and whose main diagonal consists of the KMO measures of the individual variables is known as the Anti-image Correlation Matrix.
Collinearity and Haitovsky’s Test
At the other extreme of testing correlations that are too low is the case where some variables correlate too well with each other. In this case, the correlation matrix approximates a singular matrix, and the mathematical techniques we typically use break down. A correlation coefficient between two variables of more than 0.8 is a cause for concern. Even lower correlation coefficients can be a cause for concern since two variables correlating at 0.9 might be less of a problem than three variables correlating at 0.6.
Multicollinearity can be detected by looking at det R where R = the correlation matrix. If R is singular then det R = 0. A simple heuristic is to make sure that det R > 0.00001. Haitovsky’s significance test provides a way for determining whether the determinant of the matrix is zero, namely define H as follows and use the fact that H ~ χ2 (m) where
![]()
and k = number of variables, n = total sample size and m = k(k – 1)/2.
Figure 8 carries out this test for Example 1 of Factor Extraction.
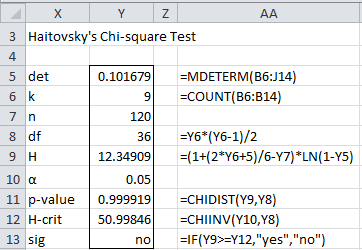
Figure 8 – Haitovsky’s Test
The result is not significant, and so we may assume that the correlation matrix is invertible.
Sample Size
In addition to the KMO measures of sample adequacy, various guidelines have been proposed to determine how big a sample is required to perform exploratory factor analysis. Some have proposed that the sample size should be at least 10 times the number of variables and some even recommend 20 times. For Example 1 of Factor Extraction, a sample size of 120 observations for 9 variables yields a 13:1 ratio. A better indicator of sample size is summarized in the following table:
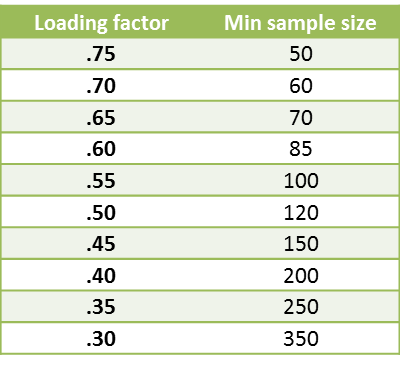
Figure 9 – Sample size requirements
The table lists the sample size required based on the largest loading factor for each variable. Thus if the largest loading factor for some variable is .45, this would indicate that a sample of at least 150 is needed.
Per [St], a factor is reliable provided
- There are 3 or more variables with loadings of at least .8
- There are 4 or more variables with loadings of .6 or more
- Finally, there are 10 or more variables with loadings of .4 or more and the sample size is at least 150
- Otherwise, a sample of at least 300 is required
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
References
Haitovsky, Y. (1969) Multicollinearity in regression analysis: a comment. Review of Economics and Statistics, 51 (4), 486-489.
https://www.jstor.org/stable/1926450
Field, A. (2009) Discovering statistics using SPSS (3rd Ed). Sage.
https://www.researchgate.net/profile/Abdelrahman-Zueter/post/What_are_the_conditions_for_using_Ordinal_Logistic_regression_Can_anyone_share_the_various_regression_methods_and_their_application/attachment/59d637d8c49f478072ea5080/AS%3A273691429015552%401442264529487/download/DISCOVERING+STATISTICS.pdf
Wikipedia (2013) Kaiser-Meyer-Olkin test
https://en.wikipedia.org/wiki/Kaiser%E2%80%93Meyer%E2%80%93Olkin_test
Hello;
Can you share anti-image correlation matrix MSA’s formula with me? Please
Hello Emine,
You can download the spreadsheets for any example on the website from
Examples Workbooks
Charles
Hello! Thank you for this resource.
I am getting a #NUM! error in each cell within the inverse of correlation matrix, partial correlation matrix, and KMO tables. Everything else looks like it was calculated. What could explain this error?
Thank you!
Hello Anna,
If you email an Excel file with your data and results, I will try to figure out why you are getting the #NUM! errors.
Charles
I am looking for the explanation about the detailed procedures how to conduct the statistical analysis based on Ajzen’s Theory of Planned Behaviour. Namely the statistical part (statistical details) is not clear enough. Could you suggest some useful website about that?
Sorry, but I am not familiar with Ajzen’s Theory of Planned Behaviour.
Charles
is there KMO and Bartlet test solved example in excel sheet?
Yes, there is an example in the Multivariate Examples file which you can download from the website.
Charles
Are the negative values for Rotated Factor Loading acceptable. (When above 0.7 but negative)
Sure, you can have negative factors.
Charles
Wonderful Charles Thanks
In doing a KMO test, when making the inverse of the sample correlation matrix, what should I do if certain values on the principal diagonal come out as negatives? This then makes the diagonal square-root function invalid as you obviously can’t sq-root a negative number. Is there a way to resolve this as it inhibits going further and getting to the KMO values?
As a side note, your site is fantastic and a great resource.
Dave,
The correlation matrix is what is called a positive definite matrix, and so you should not get negative values on the diagonal. I can see this happening only if you have made an error or you have been forced to use pairwise correlations in calculating the correlation matrix because of missing data. If you send me the spreadsheet with the data I can check to see what went wrong.
Charles
Thank you for the explainer about how it is not desirable to have the sum of partial correlations be bigger than the total correlations. It was presented in my class as a fact, which I now better understand!
Hello
It so nice piece of work…
I am seeking answer regarding reliability and validity in Excel and R programming.
In spss i have performed reliability test, but for validity there is confusion, what to do.
As convergent means all converge on their dimensions..should it mean correlation of item to variable
Please reply
Simon,
I don’t understand your question. Please clarify.
Charles
Dear Charles,
Thank you for sharing this.
I am having problem with the Box test. I read through your other articles but could not find the answer. How do I create the input matrix (L5:M6 in figure 3)? I can understand the sample size, but for the 1s, I believe it is more than simply type in 1s, because I tried and it did not work. Thank you.
Best regards,
Boyd
Dear Boyd,
The cells in the first column point to the first cell of each matrix being tested. E.g. in Figure 3, cell L5 contains the formula =B6 (i.e. the first cell of the correlation matrix) and cell L6 contains the formula =B19 (i.e. the first cell of the identity matrix). The values of both of these cells are 1, but, as you correctly stated, you can’t simply enter a 1; you need to enter the formulas.
You can get more information on the webpage https://real-statistics.com/multivariate-statistics/boxs-test-equality-covariance-matrices/real-statistics-boxs-test-support/.
Charles
Charles:
Thank you for your reply. I also read the article in the link you send me. That is very helpful. However, I still could not get it. Maybe I misunderstood, I tried =B6 and =B19 (point to the first cells of covarience matrix and identity matrix, respectively) as well as simply entered 1, neither gave me an answer from Box tests. Instead, all cells showed #value.
The matrix I want to test is a 3*3, (|1, 0.082464444
, -0.059466125
||0.082464444
, 1, -0.165151464
||-0.059466125
, -0.165151464
, 1|), and an 3*3 identity matrix. Do you know what is wrong with my process?
Thank you.
Best,
Boyd
Boyd,
To see this more clearly, you can download the Excel spreadsheet that I used for Figure 3. Download the Multivariate Examples Workbook by following the instructions on the webpage https://real-statistics.com/free-download/real-statistics-examples-workbook/. The spreadsheet can be found on the tab called Box Factor.
Charles
Charles,
From my understanding, =B6 and =B19 only gather information of the first cells of each matrix, I think there should be something that I am missing here, but I could not figure out. Could you help me with it? Thank you.
Best regards,
Boyd
Boyd,
The reason this is confusing is that I used a bit of a trick. Instead of the software using the value of the cells (i.e. 1) the software uses the address of the cells, i.e. B6 and B19. This tells the software where to find the matrices that are being compared.
Charles
Dear Charles:
I proceeded with a factorial analysis using Real Statistics 2.15, and I obtained an error in the inverse correlation matrix: the values are so huge. For that reason, Real Statistics can’t calculate neither the Partial correlation Matrix nor KMO. I review all the formulas used by Real Statistics, and all of them seem OK, so I suppose that my correlation matrix is bad conditioned. I am using 24 variables for the analysis: six questions (related to 6 dimensions of organizational culture) that have four options that must be numerically evaluated (4 types of organizational culture; the sum of the four options must be equal to 100 for each dimension).
Is bad conditioning related to the mixed 4 types of dependent variables? The error in the inverse correlation matrix is not present when I use factorial analysis for each type of dependent variable (6 independent variables for each type of dependent variable).
In SPSS I didn’t obtain the error for de inverse correlation matrix when using 24 variables in factorial analysis. So, it was possible to calculate KMO.
I hope you can answer this question.
Thank you.
William Agurto.
William,
Is the (partial) correlation matrix 24 x 24 or is it larger?
Charles
Charles:
Both (correlation matrix and partial correlation matrix) are 24×24. All the values in partial correlation matrix are #NUM!, because Inverse correlation matrix (24×24 also) has too huge numbers. Due to that, I think that the correlation matrix is bad conditioned, but I don’t know why (Excel 2010 executes the routine using MINVERSE function; that’s OK).
If you prefer, I can send you my Excel file.
Regards.
William Agurto.
Charles:
I forgot to mention that the problem is only present in inverse correlation matrix (and, obviously, for partial correlation matrix and KMO, because they’re related). Results in Real Statistics 2.15 are the same as those obtained in SPSS for the rest of the analysis: communalities for factor matrices, e-values, scree plot (with no approximations: are identical). The problem is the calculus of the correlation’s matrix inverse. Excel cannot calculate it in a correct way. Because of that I suppose my correlation matrix is bad conditioned, but I don’t know if that is common in this type of analysis, or if the error is related to the mixing dependent variables (four dependent variables).
Regards.
William Agurto.
William,
If it is poorly conditioned I am surprised that SPSS didn’t flag that.
Charles
William,
Yes, it would be best to send me the file.
Charles
Charles:
I sent the Excel file for your analysis.
Thank you.
Thanks for this wonderful statistics package and website.
In the passage starting “In addition to the KMO measures of sample adequacy…” When you wrote “Some have proposed that the sample size should be at least 10 times the sample size…” , I suppose you actually meant “…the sample size should be at least 10 times the number of variables…”?
Ellen,
You are correct. Thanks for finding the typo. I have now made the correction. I am very pleased that you like the website.
Charles