Introduction
On this webpage, we discuss blocking and randomized complete block design (RCBD). See also the following related webpages:
- Follow-up Testing for RCBD
- Efficiency of RCBD vs. CRD
- RCBD with one missing data element
- RCBD using regression
- Design with missing data using regression
- Real Statistics support for RCBD with missing data
- RCBD with replications
Blocking
Blocking is a technique for dealing with nuisance factors, i.e. a variable which is not of interest, except that it has some influence on the variables that are of interest. For the design described in CRD & RCDB, the Farm is such a nuisance factor since each farm potentially has different levels of moisture, fertility, etc.
In agriculture, a block consists of contiguous plots of land that share the same characteristics (moisture, fertility, acidity, etc.). If, for example, we want to test the difference between different fertilizers on crop yield, we can apply a different fertilizer (the treatment) at random to different plots in the block (therefore controlling for the nuisance factors).
If the nuisance variable is known and controllable, then we use blocking. While if the nuisance variable is known, but uncontrollable, we can use ANCOVA, while if the nuisance variable is unknown and/or uncontrollable, then we must rely on randomization to balance out its effect.
Model Design
We now consider a randomized complete block design (RCBD). Here, a block corresponds to a level in the nuisance factor.
The model takes the form:
![]()
which is equivalent to the two-factor ANOVA model without replication, where the B factor is the nuisance (or blocking) factor. As you can see from the equation, we use blocking to reduce the variability of the error term. This results in a more accurate way to detect differences between the treatments.
Note that the one-way ANOVA model corresponds to what is called a completely randomized design (CRD).
In a randomized complete block design, we assign the seeds such that each of the three fields in any farm is assigned a different seed type.
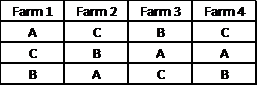
This picture takes the following form when we add the yield:
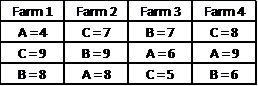
Actually, the order of the fields within each farm is not important in the analysis, and so we can view the yields per field in the following form:
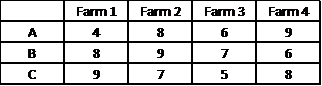
In fact, we will use the transpose of this picture, so that the treatments correspond to the columns of the data representation and the rows correspond to the blocking factor.
Example
Example 1: A company plans to introduce a new type of herbicide, and wants to determine which dosage produces the best crop yield for cotton crops. Four fields are available for testing, with each field having fairly uniform characteristics (size, moisture, fertility, etc.), although there are some differences between the fields. Each field is divided into 6 equal-sized plots, with dosages of 5, 10, 15, 20, 25, and 30 units of herbicide assigned to the plots at random. The yields are as shown in Figure 1.
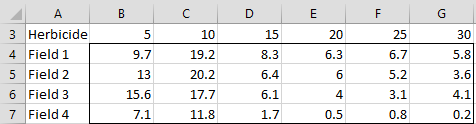
Figure 1 – Yield based on herbicide dosage per field
Two Factor ANOVA Tool
We use a randomized complete block design, which can be implemented using Two Factor ANOVA without Replication. A key assumption for this test is that there is no interaction effect. We test this assumption by creating a chart of the yields by field, as shown in Figure 2.
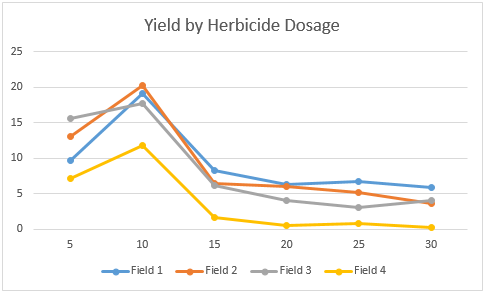
Figure 2 – Chart of the yield
We see that the lines for the four fields are roughly parallel, which indicates that the interaction assumption is reasonable.
We now run the Real Statistics Two Factor ANOVA data analysis tool using the data in Figure 1 as input, selecting the Excel input format and inserting 1 in the Number of Rows per Sample field. The main part of the output is shown in Figure 3.
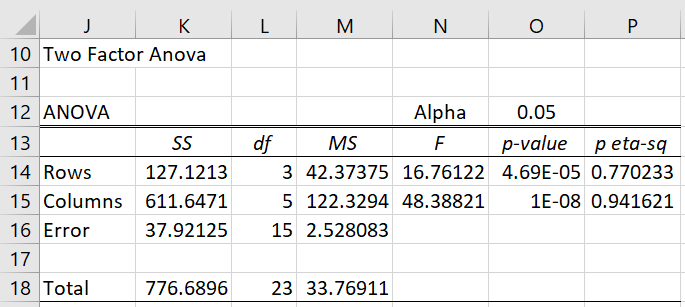
Figure 3 – RCBD using ANOVA
The rows correspond to the blocking factor and the columns correspond to the treatments. We are really only interested in the columns factor, and see that there is a significant difference between the dosages (p-value = 1E-08).
RCBD Analysis Tool
Alternatively, we can use the RCBD Anova data analysis tool to get the same result. Here we press Crtl-m, choose the Analysis of Variance option, and then select the Randomized Complete Block Anova option. You now fill in the dialog box that appears as shown in Figure 4.

Figure 4 – RCBD data analysis tool dialog box
The output shown in Figure 5 is very similar to that shown in Figure 3.
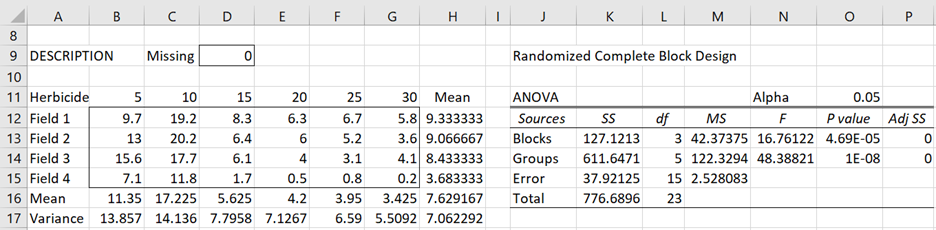
Figure 5 – Randomized Complete Block Anova
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
References
Montgomery, D. C. (2012) Design and analysis of experiments. 8th ed. Wiley
https://faculty.ksu.edu.sa/sites/default/files/douglas_c._montgomery-design_and_analysis_of_experiments-wiley_2012_edition_8.pdf
Hale, I. (2016) Randomized Complete Block Designs (RCBDs)
No longer available online
Runcie, D. (2023) Experimental design and analysis at UC Davis
https://deruncie.github.io/PLS205_course/Course_content.html
Penn State (2025) Blocking
https://online.stat.psu.edu/stat503/lesson/4
Q3. A researcher who studies the handling of fresh produce plans to conduct a study to evaluate the effect of maturity level and fruit size on the firmness level of tomato fruit. Maturity level is divided into three levels (unripe/green, half-ripe, and ripe), and fruit size is also divided into three levels (small, medium, and large). The experiment is designed using a Random Complete Block Design (RCBD). Analyze variance using the software SPSS, JASP, PSPP, and EXCEL, and write a comprehensive analysis of the results.
Maturity Level (Tingkat Kematangan) Replication (Ulangan) Small (Kecil) Hardness (kgf) Medium (Sedang) Hardness (kgf) Large (Besar) Hardness (kgf)
Unripe (Mentah) 1 15.5 14.6 14.8
2 16.1 14.5 15.8
3 14.6 15.5 14.3
4 16.3 16.5 14.2
5 15.5 15.3 15.5
Half-ripe (Setengah matang) 1 12.5 12.6 13
2 11.9 12.5 12.8
3 12.6 11.7 12.3
4 12.3 12.5 12.2
5 11.9 12.3 12.5
Ripe (Matang) 1 10.7 11.1 10.1
2 9.8 10.2 10.4
3 10.1 9.8 10.3
4 10.5 10 9.7
5 11.2 10.1 9.9 . Please could help provide steps for me to analysis this day.
Hi Samuel,
Looks like a homework assignment about RCBD. What is your question for me?
Charles
thank you Mr. Charles.
If I have 8 different treatment insecticides and 3 replicates against white fly and i need to test the efficacy of the treatments for two season (
2 years).
Hello Mohamed,
What hypothesis or hypotheses do you want to test? What constraints (in terms of resources) do you have if any?
Charles
Charles,
What if the data show that the potential nuisance factor turns out to be not a problem, resulting in a large p-value for blocks? Would it be better to use a Completely Randomized Design to evaluate the effect of the Treatment Groups? In Example 1, if 2 is subtracted from all yields in Field 1 and 4 is added to all yields in Field 4, the Blocks are no longer significantly different and the effect of herbicide dosage appears to be better defined with a CRD.
Thanks in advance for your thoughts on this approach,
Dave,
CRD is the way to go unless you have restrictions. If the approach that you have suggested yields a CRD that is good provided:
1. You can still test the hypothesis that you originally wanted to test, and
2. The approach that you decided to use is not based on any information that you collected based on another test (RCBD, CRD, etc.) that you performed previously
Charles
Charles,
Thanks for these insights. I also discovered your page on Relative Efficiency of RCBD and CRD. It turns out that the Example 1 data have a blocking RE of 3.06, whereas the modified data described above gave a RE of only 1.06, which supports using the CRD instead of the RCBD.
Dr. You do an amazing job here. I am trying to compare four okra varieties grown in open field and greenhouse for plant height, length of leaf, length of pod. How do I designe this experiment and what statistical tool will be used to analyse the data?
Hello Eugene,
If you are comparing the four varieties based on plant height, leaf length and pod length, then generally you should start by using MANOVA since you have multiple dependent variables.
The experimental design (completely randomized design, randomized complete block design, etc.) depends on the constraints you have.
Charles
Hi Charles,
If I have 4 different treatment rooms (4 sections per room but sections did not consider replicate in my case because of air quality study) and have 6-week samples. Since I don’t have any replicates, Should I consider week as a block or replicate? If I will consider week as a block then I can say it as CRBD? Do I have to do one-way ANOVA or TWo-way ANOVA?
Sorry, but I don’t understand the scenario that you are describing. Why are the sections not replicates? What is the relationship between the 6-week samples and the rooms and sections? What hypothesis are you trying to test?
Charles
Dr. Charles,
Since I have 4 treatment room, one treatment in each room (one is control). Although each room have 4 section in it, we cannot consider as replicate because we are measuring dust concentration and section are not completely sealed plus dust can move from one section to another. Room number is our limitation.
Hypothesis is dust level will differs after placing treatment. so, if we will consider room as a replicate or block, I got data significantly different. Can I do that or not?
Room is treatment
Week is dust measuring or sample taking
Unfortunately, I still don’t understand the scenario sufficiently well to be able to answer your questions.
Charles
Sir, my experiment is pot experiment at two locations (Factor C) repeated for two years. At each location there are 2 factors. Factor A has two levels and Factor B has 6 levels. Thus, there are 12 treatments. Each treatment has 3 replications (R).
So there are 2*6*3 = A*B*R= 36 pots (experimental units) at each location.
I will use Factor A and B as fixed factor and Factor C as random factor.
Which design I should use to analyze in Excel?
I want to see the individual as well as interaction effect of factor A and Factor B om yield and soil microbial population at two different times. I also want to see whether the factor A and B differently influence the variables at different locations.
Hello,
If I understand correctly, you have 2 levels for Factor A, 6 levels for Factor B and 2 levels for Factor C, for 2x6x2 = 24 combinations, resulting in 24×3 = 72 data elements (ignoring Time for a moment). This can be analyzed using 3 Factor ANOVA, as described at
Factorial ANOVA
But you also mentioned that you have data for two years. This introduces more complexity, requiring the use of Three Factor REpeated Measures ANOVA or Three Factor MANOVA.
Charles
Dear Charles,
I should analyse a multi-year experiment based on a RCBD:
I have one experimental factor with 3 levels (3 treatments) and 3 blocks
the experiment was repeated 3 times (in 3 different years).
I suppose that the experimental factor is a fixed factor while block and year are random factors.
I am interested in studying the effect of year and experimental factor on a dependent variable
I am wondering whether this experiment could be analysed using Excel and how, could you please suggest some ideas?
thank you very much
best regards
Donato
What hypothesis or hypotheses are you looking to test?
If I understand correctly, your scenario can be interpreted as a repeated-measures ANOVA. Here you have one between-subjects factor (what you call the experimental factor) and one within-subjects factor (the 3 years).
This can be modelled in Excel as described at
One between-subjects and one within-subjects factor
Charles
Sir, my experiment is similar with Annes’s. I want to ask the same question.
Metric will be used is survival rate.
Hypothesis are first –
Ho: There is a clear difference on the effectiveness of treatments towards towards seeds.
H1: There is no difference on the effectiveness of treatments towards towards seed.
Second –
Ho: there is a clear difference on the survival rates of the two type of seed.
H1: there is no difference on the survival rates of the two type of seed.
Maddle,
If you don’t have any constraints then you can use a one-factor ANOVA (or even a two independent sample t-test if there are only two treatments).
Charles
What if I collect binary data (survived & mortal seedlings). Is ANOVA still applicable?
By the way, I use two type of seeds and 3 type of treatments.
Maddie,
Probably not since the normality assumption won’t be met.
Which test to use depends on the details, particularly what hypotheses do you wish to test and the type of data that you have. E.g. Cochran’s Q Test is a non-parametric test for ANOVA with repeated measures where the dependent variable is dichotomous.
Charles
What experimental method I will use?
Treatments (6) for both new and old seeds. 10 seeds per treatment, how is that?
Anne,
What metric are you using?
What hypothesis do you want to test?
Charles
please i conducted an experiment using RCBD with 6 treatments to find out the the critical period for weed control in finger in my state. i don’t know how to enter the data in excel to conduct my analysis
Eric,
Data is entered as shown in Figure 1 to obtain the results for the RCBD in Example 1.
How do you define the critical period for weed control?
Charles
Hi Charles,
Say I have 30 progenies, each with 3 replications, and 5 plants /replication could you please outline a workflow to follow to generate an RBD for field experiment, how shall i do this in Excel.
Thanks
I don’t completely understand the experiment that you are describing. What hypothesis are you testing? How does the experiment differ from that in Example 1?
Charles
I have 100 genotypes in three replications and want to test them for yield and other traits vis a vis check or control variety. Shall I go for CRD or RCBD
This depends on the details. What hypotheses are you trying to test? What is the relationship between the genotypes and the check or control variety? Are there any constraints in how you conduct your experiment?
Charles
Hi Charles,
So i am conducting an experiment/study about pasta straws. Is this RCBD or CRD? And what type of statistical app is the best for this kind of study? Thank you.
Hi Drey,
It depends on what hypotheses you are trying to test and what constraints you have. In general, the default would be CRD, but constraints on resources might lead you to using RCBD. It depends on the details.
Charles
Hi Charles,
I have planted 5 different varieties of the same crop species in RCBD, each crop variety in 3 different treatments (seed sizes) to check the effect of seed size on growth and yield. What statistical analysis can I use for this data?
Hello,
Thank you so much for sharing information.
I plant 10 chilli varieties (3 plants per one variety) inside greenhouse. For this type of experiment, how can I consider which experimental design it is?
Please could you advise me which kinds of data analysis should I use?
Thank you so much.
The design depends on a number of factors, especially what hypotheses do you want to test.
Charles
Hi Charles,
Thank you for taking out time to share your knowledge.
I have data from a RCBD with 5 treatments and 3 replicates. I collected data from four plants per experimental unit. I would like to ask how I can enter this data, get means of each unit and eventually combine these means to analyse the data like you’ve done here.
Thank you
Hello Ena,
I haven’t included RCBD with replication on the Real Statistics website yet. I plan to add this capability in one of the next releases.
Charles
First try to collect data from more number of plants.
then, yes average it out so you get 15 data points.
You can code in spss, its much simple
if i have disc plough, disc harrow, mouldboard plough, use for five treatment, what will the block design be
Hello Inusa Adamu,
The block design will depend on many factors and so I cant give an answer based on the information that you have supplied.
Charles
Charles,
I would like to report errors on Figure 3 of the “RCBD w/ 1 missing data element” section.
For the adjusted RCBD Anova analysis table, the SStotal should be 636.9843 rather than 654.7848. Therefore the SSe should be correctly accordingly as well.
One question I have is that when I ran the same data (ie, 1 missing cell value) using the “Regression” option of the RCBD analysis tool, the SSgroup (477.1427) is not the same as the adjusted SSgroup (494.9431) based on the RCBD analysis. Should they be the same?
-Sun
Charles,
Please disregard the first part of the error report I made. I found out why the SStotal between my calculation and Figure 3.
My SStotal is directly from the original data with the one missing cell based on DEVSQ, while the Figure 3 SStotal is obtained from =DEVSQ(the imputed missing value-SS (block correction) – SS(group correction).
Hello Sun,
Do you still want me to respond to your question in the second paragraph?
Charles
Yes, please. I read your statement on the web stating that the one missing cell RCBD adjusted Anova results are not the same as the RCBD regression results. As I learned now that the SStotal and SSerror are differently calculated (ie, SS block and group correction factor), I wonder whether that was the main reason for the difference. Was that what you meant to describe. If so, it would be more informative to state such on the web.
Thanks,
-Sun
Hello Sun,
I believe that I stated that the results would be different because when I tried both approaches I got different answers. I suggest that you try both approaches with one missing data element to see where the results differ. (Perhaps you have already done this).
Charles
Hi charles, could you please help me with this question
with possible randomizations for a CRD and RCBD, Be sure you assign treatments to the experimental units in such a way that the CRD cannot be mistaken for a RCBD. Treatment=5, replications=3. (code for random number (round(rununif(25), digit=3))
Leo,
Sorry, but I don’t know what (round(rununif(25), digit=3)) refers to.
As far as the rest of the statement, this is answered by referring to the following two webpages
https://real-statistics.com/design-of-experiments/completely-randomized-design/
https://real-statistics.com/design-of-experiments/completely-randomized-design/randomized-complete-block-design/
Charles
Dear Sir,
I Find this your Update on RCB Design interesting and capture my attention as is part of my thesis.
please can i have your Private Mobile Number
Usman,
I am pleased that you find this webpage interesting. In the next couple of days, I expect to update the information about RCBD to include the cases where some data is missing.
Sorry, but I don’t give out my private mobile number.
Charles
Thanks to you Mr. Charles.
I will be waiting for the update sir
Assuming that in the course of the conduct of the study, the entry under dosage 5 units of field 3 was attacked by rodents and no data was obtained for this particular entry, how would I calculate the missing observation ?
Maria,
I have not yet addressed the issue of missing data for a Randomized Complete Block Design. I am currently in the process of expanding the missing data capabilities of the Real Statistics website and software, especially by using the EM Algorithm. I will try to see if I have enough time to add support for the type of missing data that you have requested.
Charles
Update: I plan to include this topic in the next release, which should be available this month.
Could you clear the issue of determining the plots in a random pattern after developing random number from excel.
Scenario: 3 treatments, 3 replicates total of 9 plots
Are you asking how you randomly assign 9 subjects (i.e. plots) to 3 treatments?
If so, label the subjects 1, 2, …, 9 (column A). Now shuffle the numbers 1 through 9 (column B). This can be accomplished using Real Statistics SHUFFLE function or in Excel as described at
https://real-statistics.com/sampling-distributions/sampling/
Next place the formula =MOD(B1,3)+1 in cell C1, highlight the range C1:C9 and press Ctrl-D.
Now suppose the result is as shown below
A.B.C
1.3.3
2.7.1
3.9.3
4.2.2
5.4.1
6.8.2
7.1.1
8.6.3
9.5.2
Column C shows the treatment (1,2,3) assigned to each subject. Thus subjects 2, 5 and 7 are assigned to treatment 1.
Charles
Thank you Charles!
I’m using that website thanks