Objective
We now provide proofs of properties presented in Multivariate Regression Basic Concepts.
Proofs (part 1)
Property 1:
B = (XTX)-1XTY
Proof: By univariate regression properties
B = [B1 B2 ⋅⋅⋅ Bm]
= [(XTX)-1XTY1 (XTX)-1XTY2 ⋅⋅⋅ (XTX)-1XTYm]
= (XTX)-1XT[Y1 Y2 ⋅⋅⋅ Ym] = (XTX)-1XTY
Property 2: B minimizes the trace
Tr((Y – XB)T(Y – XB))
Proof: The m × m SSCP matrix S
S = (Y – XB)T(Y – XB)
has diagonal terms which are non-negative scalars of the form
![]()
Now
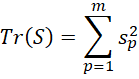
Since the values bjp minimize each term in the above sum, they also minimize the sum.
Property 3:
E[ε] = 0
Proof: This is a consequence of the fact that E[εp] = 0 for all p
Property 4: B is an unbiased estimator of β; i.e. E[B] = β
Proof: By Property 1
B = (XTX)-1XTY
But
Y = Xβ + ε
Thus
B = (XTX)-1XTY = (XTX)–1XT(Xβ+ε)
=(XTX)–1XTXβ + (XTX)–1XTε
= (XTX)–1(XTX)β + (XTX)–1XTε
= β + (XTX)–1XTε
Thus
E[B] = E[β + (XTX)–1XTε] = E[β] + E[(XTX)–1XTε]
= β + (XTX)–1XTE[ε] = β + 0 = β
since E[ε] = 0 by Property 3.
Proofs (part 2)
Property 5:
cov(Bp, Bq) = σpq(XTX)-1
Proof: Using univariate regression properties
Bp = (XTX)-1XTYp= (XTX)–1XT(Xβp + εp)
= (XTX)–1XTXβp + (XTX)–1XTεp = βp + (XTX)–1XTεp
Thus
Bp = βp + (XTX)–1XTεp
and so
Bp – E[Bp] = βp + (XTX)–1XTεp – βp = (XTX)–1XTεp
Similarly
Bq – E[Bq] = (XTX)–1XTεq
Hence
cov(Bp, Bq) = E[((XTX)–1XTεp)((XTX)–1XTεq)T]
= E[(XTX)–1XTεpεqTX(XTX)–1] = (XTX)–1XTE[εpεqT]X(XTX)–1
= (XTX)–1XT(σpqI)X(XTX)–1
The last equality is a result of the fact that E[εpεqT] = E[(εp-E[εp])(εq-E[εq])T] = cov(εp,εq) = σpqI since E[εp] = E[εq] = 0. Finally,
cov(Bp, Bq) = (XTX)–1XT(σpqI)X(XTX)–1
= σpq(XTX)–1(XTX)(XTX)–1 = σpq(XTX)–1
Property 6:
E[Ep] = 0
Proof: Here Ep is the pth column of E = [eip].
E[Ep] = E[Yp–XBp] = E[Yp] – XE[Bp] = E[Yp] – Xβp
The last equality results from the fact that Bp is an unbiased estimator of βp.
But
Yp = Xβp + εp
and so
E[Yp] = E[Xβp + εp] = E[Xβp] + E[εp] = Xβp + 0 = Xβp
Putting everything together, we have
E[Ep] = E[Yp] – Xβp = Xβp – Xβp = 0
Property 7:
cov(Yp, Yq) = σpq
Proof:
cov(Yp, Yq) = (Yp – E[Yp])T(Yq – E[Yq]) = (Yp – Xβp)T(Yq – Xβq)
= εpTεq = cov(εp, εq) = σpq
Trace properties
Before we proceed, we recall some properties of the trace of a square matrix. In particular
Property A:
Trace(Im) = m
Trace(AB) = Trace(BA)
Trace(bA) = bTrace(A)
Trace(A+B) = Trace(A) + Trace(B)
In addition, we prove the following properties.
Property B: For any square matrix A
E[Trace(A)] = Trace(E[A])
Proof: For A = [aij]
E[Trace(A)] = E[∑aii] = ∑ E[aii] = Trace(E[A])
Property C: For any n × n matrix A and n × 1 matrices Y and Z
E[YTAZ] = Trace(A cov(Y,Z)) + E[Y]TA E[Z]
Proof: First note that AZ is also a n × 1 matrix. Thus, as for any covariance
cov(Y, AZ) = E[YTAZ] – E[Y]TE[AZ]
= E[YTAZ] – E[Y]TA E[Z]
Thus
E[YTAZ] = cov(Y, AZ) + E[Y]TA E[Z]
Also
cov(Y, AZ) = E[(Y–E[Y])(AZ–E[AZ]) = E[(Y–E[Y])A(Z–E[Z])
But cov(Y, AZ) is a scalar, and so cov(Y, AZ) = Trace(cov(Y, AZ)). Using the commutivity property of Trace, we obtain
cov(Y, AZ) = Trace(E[(Y–E[Y])A(Z–E[Z])) = Trace(A E[(Y–E[Y])(Z–E[Z]))
= Trace(A E[(Y–E[Y])(Z–E[Z])) = Trace(A cov(Y, Z))
Putting it all together, we get the desired result
E[YTAZ] = cov(Y, AZ) + E[Y]TA E[Z]
= Trace(A cov(Y,Z)) + E[Y]TA E[Z]
Hat matrix properties
We now present some properties of the hat matrix
H = X(XTX)–1XT
Property D: H is symmetric
Proof:
HT = (X(XTX)–1XT)T = X((XTX)–1)TXT = X((XTX)T)-1XT = X(XTX)–1XT = H
Property E: H is idempotent
Proof:
H2 = (X(XTX)–1XT)2 = (X(XTX)–1XT)(X(XTX)–1XT)
= X(XTX)–1(XTX)(XTX)–1XT = X(XTX)–1XT = H
Property F: I – H is symmetric and idempotent
Proof: The result follows from Properties D and E since
(I – H)T = IT – HT = I – H
(I – H)2 = (I – H)(I – H) = I – 2H + H2 = I – 2H + H = I – H
Property G: From Property F, it follows that
(I – H)T(I – H) = I – H
Property H:
Trace(I – H) = dfRes
Proof: Using Property A
Trace(H) = Trace(X(XTX)–1XT) = Trace(XTX(XTX)–1) = Trace(I) = k+1
Trace(I – H) = Trace(I) – Trace(H) = n – Trace(H) = n – k – 1 = dfRes
Proofs (part 3)
Property 8:
E[EpTEq] = σpqdfRes
Proof: Here dfRes = n – k – 1. First we note that
EpTEq = (Yp–XBp)T(Yq–XBq) = (Yp–HYp)T(Yq–HYq)
= ((I–H)Yp)T((I–H)Yq) = YpT(I–H)T(I–H)Yq = YpT(I–H)Yq
The last equality follows from Property G. Thus
EpTEq = YpT(I–H)Yq
By Property C
E[YpT(I–H)Yq] = Trace((I–H) cov(Yp, Yq)) + E[Yp]T(I–H)E[Yq]
By Properties 7 and A,
Trace((I–H) cov(Yp, Yq)) = Trace(I–H) ⋅ Trace (cov(Yp, Yq))
= dfRes ⋅ Trace (σpq) = σpq dfRes
Finally, note that
E[YpT](I–H)E[Yq] = (Xβp)T(I–X(XTX)–1XT)(Xβq)
=(Xβp)T(Xβq) – βpTXTX(XTX)–1XTXβq = (Xβp)T(Xβq) – βpTXTXβq = 0
Putting it all together, we have
E[EpTEq]= E[YpT(I–H)Yq] = Trace((I-H) cov(Yp, Yq)) + E[Yp]T(I–H)E[Yq]
= σpqdfRes + 0 = σpqdfRes
Property 9: SSE/dfRes is an unbiased estimate for Σ; i.e. E[SSE] = E[ETE] = dfResΣ
Proof: This is a consequence of Property 8.
Property 10:
cov(Bp, Eq) = 0 cov(B, E) = 0
Proof: The proof of the first assertion is similar to that for Property 8. The second assertion follows from the first.
References
Johnson, R. A., Wichern, D. W. (2007) Applied multivariate statistical analysis. 6th Ed. Pearson
https://mathematics.foi.hr/Applied%20Multivariate%20Statistical%20Analysis%20by%20Johnson%20and%20Wichern.pdf
Rencher, A.C., Christensen, W. F. (2012) Methods of multivariate analysis (3nd Ed). Wiley
Stack Exchange (2011) How to prove that the expression ….
https://math.stackexchange.com/questions/93994/how-to-prove-that-the-expression-ezaz-for-a-random-vector-z-is