We now turn our attention to some of the methods used for handling missing data. In particular, we will begin by looking at the data displayed in Figure 1.
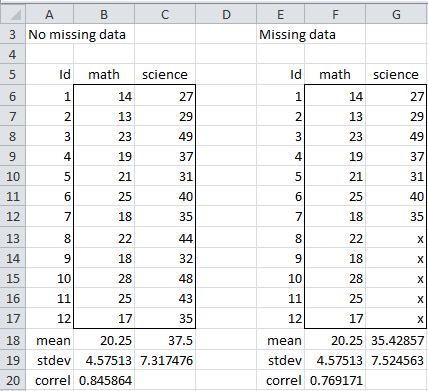
Figure 1 – Missing Data
Here we see that 5 of the 12 data elements are missing. We display the full data set, without any missing data as well. Keep in mind that, in practice, we will almost never have the luxury of knowing what the missing data values are really supposed to be.
Listwise deletion
Probably the most commonly used approach when the data range has some missing data elements is to eliminate any rows with missing data, i.e. to eliminate the ith row of X if one or more xij is missing for j = 1, …, k. This is called listwise deletion or complete case analysis (CCA).
As described in Dealing with Missing Data, this approach can be reasonable when there is only a small amount of missing data. But even a small amount of missing data can result in a large percentage of the sample being deleted. For example, even though only 20% of the data in Figure 2 is missing, no data is left after listwise deletion.
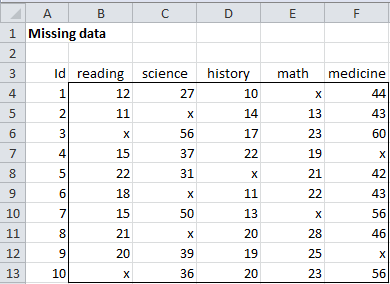
Figure 2 – Each case has some missing data
Even in less extreme cases, unless the original data set was quite large, the reduced sample size can dramatically reduce the power of whatever test is performed.
Referring to Figure 1, if we compare the regression model of the complete data (all 12 rows in range B6:C17) with that of the data using listwise deletion (7 rows in the range F6:G12), we obtain the results shown in Figure 3.
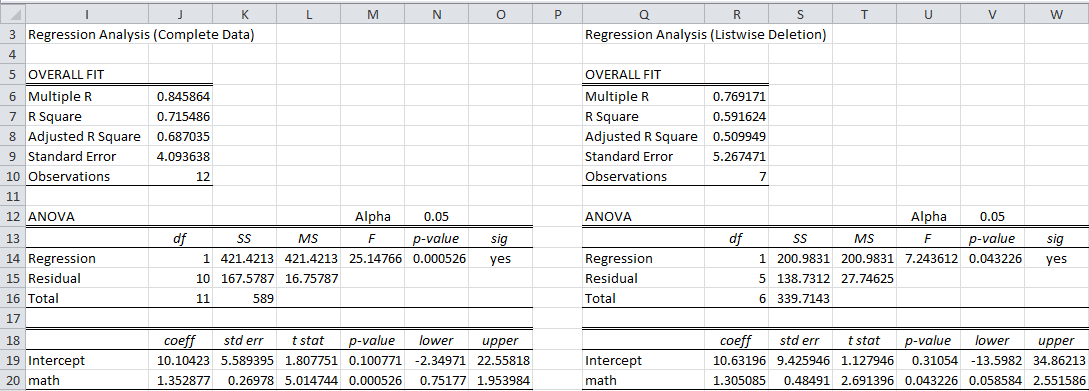
Figure 3 – Comparison of Regression Models
As we can see, the regression model for the complete data looks to be a better fit than for the incomplete data (Adjusted R of .687 vs. .509). Consequently, it appears that something is lost by eliminating 5 of 12 rows (41.7% of the data) even though only 5 of 24 data elements (20.8%) are missing.
Single imputation using the mean
As described in Dealing with Missing Data, we can impute the value of any missing data based on the values of the non-missing data. A simple approach is to fill in the missing science values from Figure 1 with the value of the mean of the non-missing data, namely 35.4287 (cell G18). This is shown in Figure 4.
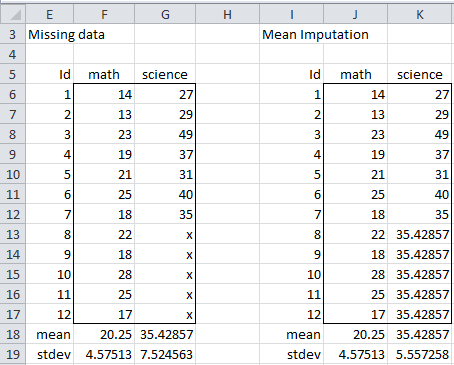
Figure 4 – Mean Imputation
The result is that the standard deviation of the science variable has decreased from 7.525 to 5.557. This is not surprising since the deviations for these last five data elements are 0. That we obtain biased values for the standard deviation is clearly not desirable.
Single imputation using regression
Another approach for filling in the missing data is to use the forecasted values of the missing data based on a regression model derived from the non-missing data. Figure 5 displays the results of this approach for the data in Figure 1.
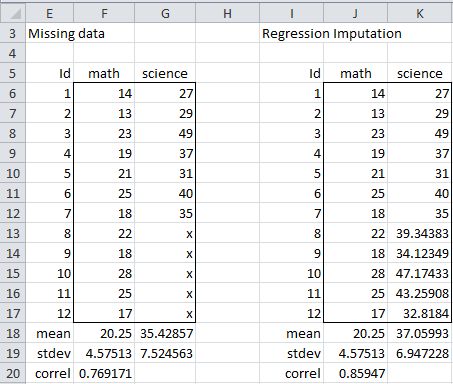
Figure 5 – Regression imputation
This time, we impute the values of the five missing cells by inserting the array formula =FORECAST(J13:J17,G6:G12,F6:F12) in the range K13:K17. Since this results in a perfect linear correlation between the math and science values for the last five data elements, it is not surprising that the correlation coefficient between math and science rises from .769 (cell F20) to .859 (cell J20). The standard deviation also falls. Regression imputation creates biased values for the correlation coefficient and standard deviation (although if the data is MAR or MCAR, the mean is not biased). Once again, this is not desirable.
Note that the estimate for the correlation coefficient produced by this approach is quite close to that observed for the complete data (cell B20 of Figure 1) since the correlation there is already quite high. The standard deviation is again lower than that for the complete model (cell C19 of Figure 1).
Single imputation using stochastic regression
We can improve the situation by adding a random component to the imputed regression values. This will artificially increase the variability. The approach used is to simply add a randomly generated value following the normal distribution N(0, s.e.), where s.e. is the standard error of the regression model on the non-missing data. Figure 6 displays the results of this approach for the data in Figure 1.
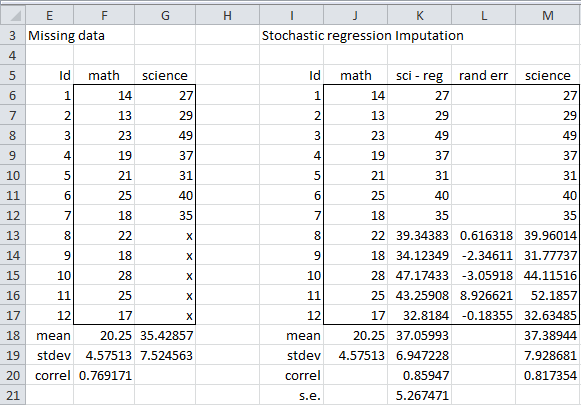
Figure 6 – Stochastic regression imputation
The value of the standard error for the regression is s.e. = 5.267, as shown in cell R9 of Figure 3 (and duplicated in cell K21 of Figure 6). Thus, we need to add the random error value calculated by the formula
=NORM.INV(RAND(),0,K$21)
to each of the imputed values shown in Figure 5 (and duplicated in Figure 6). These values (shown in column L of Figure 6) when added to the regression imputed values yield the stochastic regression values shown in column M of Figure 6.
This time, the standard deviation is increased and the correlation is decreased, as we had hoped. The actual adjustment, however, depends on the random numbers generated to create the random errors. These can be quite volatile.
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
Links
References
Baraldi, A. N. and Enders, C. K. (2010) An introduction to modern missing data analyses, Journal of School Psychology 48, 5–37.
https://pubmed.ncbi.nlm.nih.gov/20006986/
Eekhout, I. (2019) Single imputation methods. Don’t miss out.
https://www.missingdata.nl/missing-data/missing-data-methods/imputation-methods/
Hain, H. (2021) Stochastic regression imputation
This document is no longer available online.
comment
Charles – It seems like a starting point for this trouble is Little’s Test for MCAR. I have looked and don’t find it among your material. Did I miss it? Thanks. RJB
Hi Roger,
Yes, you are correct.
I don’t believe that I have included Little’ Test for MCAR.
I will try to add this in a future release.
Charles
Hi,
I have a real-estate data set which has missing data related to the ‘Year’ the estate was built. I have around 13k rows of data out of which 7k rows are missing the ‘Year’. In order to do a proper EDA – in this domain of business I am pretty sure – the ‘Year’ plays an influence in pricing of the estate. So wanted to know how we can fill the missing data of 7k rows in ‘Year’ column. And what kind of numerical data will ‘Year’ represent? Numerical Discrete or Ordinal Discrete?
The mode and mean in this case comes to year 1970, min = 1196 and max = 2018
Hello Jasbir,
EDA is a very broad topic and so it really depends on the details as to which approaches you plan to use and the nature of your data.
Generally, the best techniques for handling missing data don’t really fill in the missing data, but instead, calculate some statistic or create some model that is a reasonable estimate of the one that would result if no data were missing,
In any case, since you are performing EDA, perhaps you can use some simple approaches for filling in the missing data in order to get a better understanding the data (which is the object of EDA after all). For example, you could start by using listwise deletion and see what you get. You could then try simple imputation with regression.
Of course, if you have another variable that is directly related to the Year variable, then you might have even better success with simple imputation.
Charles
Jasbir – Real estate data is, as you have observed, a unique situation in statistics. You can find a lot of work in that area at http://www.mathestate.com. My best. RJB
Dear sir, if i have univariate data set with missing data, what should i do ?
It depends on the nature of your data. See also
Handling Missing Data
Charles
There are many techniques, some of which are described on this webpage, others at
Handling Missing Data.
What technique to use depends on many factors, including: (1) what percentage of the data is missing, (2) is there a non-random cause that data is missing, (3) what kind of data do you have, (4) what test do you need to use the data for.
Charles
dear how we can compute the missing data of preceeding cells if they are not available and later cell information is available like we have missing data from b1 to b6 and from onwards b7 we have data available
MH,
Sorry, but I don’t understand your question.
Charles
Hi Charles,
Your tutorial is awesome!
Do your know which page that i can get the formula (if with the R code is better) /notes to calculate the stochastic imputation?
Best
aisyah
Sorry, but I don’t understand your question.
Charles
Hello Charles, thanks for your tutorial.
Please could you explain to me how do you calculate the random error in a very simple manner. I know what is a standard deviation, a standard error for a sample mean and know how to calculate them but a standard error of a regression I don’ know how to calculate it.
Thanks
Ali,
See https://real-statistics.com/multiple-regression/multiple-regression-analysis/multiple-regression-analysis-excel/
Charles