The number of imputations m required is dependent on the percentage of missing data p and the accuracy (efficiency) desired. In fact, the efficiency is approximately equal to
![]()
(i.e. the relative accuracy of using m imputations instead of an infinite number of imputations). The efficiency for various values of p and m is shown in Figure 1.
% of missing data (p)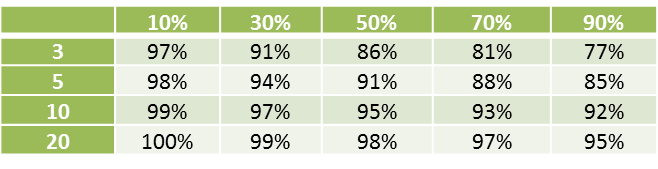
Figure 1 – Efficiency of the MI algorithm
As can be seen from the above table, if there is not too much missing data then m = 3 or 5 is sufficient. Even with extremely high amounts of missing data m = 10 or 20 should be sufficient.
The value of p is approximately equal to
![]()
where r and df are as defined in Combining Multiple Imputations.
Links
Reference
Haymans, M. W., Eekhout, I (2019) Relative efficiency. Applied missing data analysis with SPSS and (R) Studio
https://bookdown.org/mwheymans/bookmi/measures-of-missing-data-information.html#relative-efficiency
Raghunathan, T. (2016) Missing data analysis in practice. CRC Press
https://www.taylorfrancis.com/books/mono/10.1201/b19428/missing-data-analysis-practice-trivellore-raghunathan