Objective
A major component of the strategy for winning at Wordle is to make a good initial guess. One approach is to pick a 5-letter word with letters that occur most frequently in the Wordle dictionary.
Letter Frequency
If we simply look at the letters used in the 2,315 possible target words shown on the Wordle Strategy webpage, we see the following distribution of letters of the alphabet:

Figure 1 – Letter frequency
We see from Figure 1 that “e” is the letter that is most frequently used (1,233 times in total), followed by “a”, “r”, “o”, “t”, “l”, “i”, “s”, “n”, “c”. The most frequently used letter in the first position is “s”, while the most frequently used letter in the second or third position is “a”. The most frequently used letter in the fourth or fifth position is “e”.
One strategy for our initial guess is to use a word that contains the most frequently used letters. “later” is such a choice. Figure 2 contains a list of initial guesses from the basic Wordle dictionary that use the most frequent letters without repeating a letter.
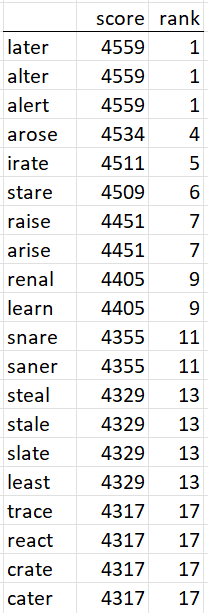
Figure 2 – Guesses based on frequently used letters
There are also quite a few words from the full, 12,497-word, dictionary that could be added to this list, including a few words that would rank higher than those that appear in Figure 2 (“orate”, “oater”, “roate”, “realo”).
Figure 1 includes multiple occurrences of the same letter (e.g. “e” in “geese”). Figure 3 provides a similar list where multiple occurrences of the same letter are only counted once. Thus, for example, 39.3% of the words in the dictionary contain the letter “a”.

Figure 3 – Letter frequency
Possible Patterns
Based on the rules for Wordle described in Wordle Strategy, after each guess that you make, Wordle responds by highlighting your guess with one of three colors, red, yellow, or grey. Thus, there are 243 (= 35) possible Wordle color codes for any guess. We will call this a “pattern”, which consists of a 5-letter word using the letters “G”, “Y”, or “*”. Here, “G” stands for green, “Y” stands for yellow, and “*” for grey. The 243 possible patterns are shown in Figure 4.

Figure 4 – Wordle Patterns
Reference
New York Times (2022) Wordle
https://www.nytimes.com/games/wordle/index.html
Some guys at MIT came up with SALET (a kind of helmet) as the best starting word.
I then took the next 10 most frequent letters, C, D, H, I, N, O, P, R, U and Y,
and came up with PRICY and HOUND.
Unless I get enough info to guess the word after PRICY, I use HOUND.
Statistically, this is the most favorable strategy for a solution in 4 guesses.
Do most commenters here play easy or hard mode? My brain prefers hard mode, which seems easier to me. I occasionally get trapped, though. I play the mini first and pick a word from it, or a word derived from it, as my starter word, as long as it doesn’t repeat letters. My current streak is only about 200.
Hi Paul,
I don’t actually know. I have never asked.
Charles
I use “OUTER” in the first line and “DAISY” in the second line and I still have four chances to guess the word which I get most of the time.
You can also use “ADIEU” in the first line and “STORY” in the second line.
Then you have four chances left to guess the word as you’ve covered all the vowels.
I’m wordle-ing with two friends and
I use: SHALT, CRONE, and then usually DUMPY
My sister uses: SLATE, ROUND, and CHIMP
and my friend uses: TRASH, and MONEY
and my friend wins the most often, usually in three turns
Based on the letter frequency chart in this article, I’ve come up with 2 starter words with the highest letter position hits, except ‘O’, which i have withheld to use in a 3rd word, if necessary.
Also easy to remember words.
They are:
CRUEL
SAINT
and if necessary
PODGY
These have generally given me a win within 3 or 4 guesses.
I have always guessed correctly within 6 guesses.
Good work, Andy.
Charles
Played 1422 missed 10- 99.3%
Max 360 – forgot to play with friend visiting- never again!
In 3- 30.9.%. In 4-40.1%
Start: STARE
2nd: if not ending E- PIONY
If ending in E- depends!
If too many options after 3- go to paper/pencil – select word to eliminate most options regardless of prior color.
Frustration: belittling of my word selection by BOT!!🤪
I like SLATE as the starter. Letter placement is key, not just overall probability. You want a good chance of hitting green early.
I usually enter the first 5-letter word that I see on a random internet page, and run from there. I haven’t struck out yet; most solutions are either at entry 4 or 3 (just one at entry 2, and one at entry 6 [whew]). Tomorrow I’ll start with CRYPT–that’s a good one!
Hi Mike,
CRYPT seems like a tough start. Curious to see how you do.
Charles
Out of 640 tries, I have 46 2nd guess wins. My average guess rate is about 3.85 guesses, and 1.09% miss rate. I almost always start with STALE or SLATE.
How does this compare to others?
Ben,
These are excellent scores.You can eliminate your miss rate by anticipating that you may get into one of those situations where you know that the target is one of say 4 words but making an incorrect guess just means that you still have 3 possible targets, and so you need to guess again and again and hope for the best. Before you get into such a situation, you may need to make a guess that can’t result in a win on that turn, but will guarantee that you will get the target within 6 guesses (or better yet 5 guesses).
Charles
I like your starting words. I’ve been starting with TRAIN but this is clearly not the most efficient first guess. My rate for 2nd guess wins is only 3.8% versus your 7.2%. My average guess rate is 3.81 and my miss rate is 0.93%
On February 15th, 2022 I was introduced to Wordle. By some unknown reason I used the word DODGE. As I watched the screen, the green letters started turning over.
D-O-D-G-E. My daughter was flabbergasted and I made some comment about this is not so hard.
Now I realize what a guess that was.
First time playing the game and batting
at 💯%. I would really like to know and wonder how many others this has happened to… Fond memory.
Not in Wordle, but an pitch and putt a hole in one at first try. All downhill after that and I retired very early.
Since there are just under 5000 words with 5 letters, that gives you a 0.02% chance of winning a random word on the first try.
It’s easy to win in one move though. Just log in and play it, then log into a different computer and win first try. 😉
Just read your “DODGE” comment Robert (right first time!). We started wordle about 2 years ago. Must have been something on tv – in Game 1 my wife put in “MOUSE” and she ‘got it in 1’ also (100%!). Each day at breakfast she looks around and chooses a random word – sunny, bread, cloud etc etc and does really well every day. I use Line 1 for any word with 3 vowels, and line 2 using the other 2 vowels. I get by most days but her scores are always quicker & better!
There’s a story in our circle about a woman introduced to Super Mastermind (5 pegs with 8 possible colors). To make it easier on her, the person set up 5 red pegs. And that was her first guess. “That’s not so hard” was her comment, too.
Have you considered strategy’s related to eliminating groups of words? I actually like CRYPT as a first word since it eliminates a lot of possibilities that often catch you out with the Y, C and P but still includes the common R and T.
Hi Cheryl,
I haven’t tried that. What sort of results are you getting? What is your average number of guesses?
There is a tradeoff between eliminating possibilities and getting to the correct answer as quickly as possible.
Charles
Hi Cheryl, I like this technique. The game reminds me of hangman so I’ve been using LYNCH as my starter. It usually works well.
Charles, having read what you and others have done, it appears that I have gone down a rather different path.
Noticing that direct hits (green) contain considerably more information than indirect hits (yellow), I’ve sought out starting words with letters positioned where they’re most likely to be found within the word: S and P in position 1, R in position 2, A in position 2 or 3, N in position 4, E and T in position 5, and so on.
When playing Octordle, I start with three standard words (CRIME, SHALT, POUND). I generally get an abundance of green hits, allowing me (more often then not) to guess all eight target words with just eight more guesses.
For Wordle, I start with CRIME. If it’s not rich in hits, I move on to SHALT. If the hit count is still low, I use POUND before moving in for the kill.
Before I stumbled onto your website, I didn’t have the benefit of knowing letter frequencies on the actual Wordle word set. I see that Y is in twelfth place in this word set, much higher than the 19th place it occupies generally. I didn’t know that when I set out to find my three “go to” words using the fifteen letters most frequently found in English words (I relied on https://www3.nd.edu/~busiforc/handouts/cryptography/letterfrequencies.html).
Here is another set that uses these same 15 letters in their same positions (SHAME, PRINT, COULD), which will therefore work just as well for Quordle and Octordle, but probably not as well for Wordle.
Hi Ron,
Despite my goal of trying to optimize the score, the important thing is to enjoy playing the game, no matter what strategy you use.
In any case, the approach described on my website obtains an average score better than 3.5, and always produces a match within 5 tries.
Charles
I have now come up with three common 5 letter words that use all of the 15 most frequent letters.
I then have three chances to solve the puzzle. If after my three words I don’t have all the letters I then look to D P M F K W to fill in.
Hi John,
How often do you solve the puzzle within 3 guesses?
Charles
Sorry, just saw your question. Not often, I usually solve in four and I often have 4 of the letters in the word, sometimes all 5. If I only have three letters, I consider the possibility that there might be double letters like ee or tt for example, or one letter appears twice. My winning figure is 98%, but I have not lost under my new method, so 100%. If your challenge is to win the game in the fewest tries, my method is not the one for you.
Just to be clear, I always put all three words in regardless of results, so I solve in 4,5 or 6, usually 4, rarely 6. However, occasionally I will solve in 3 if I have all five letters after the second word.
John,
It looks like to are having pretty good success. More importantly, you are having fun — more important than the numbers.
Charles
I also play Octordle as also Sedecordle (which needs 16 words and thus easier by the method described!).
If you don’t care about least number of steps (in any case, you need at least 8) but just to solve within the stipulated 13 steps allowed, you may use ALTER, SCION, FUDGY, NYMPH and VIXEN (in any order)!
What is the logic? If you notice, these cover all letters of alphabet excepting the least used ones i.e., Z, J, and Q while duplication of only E and N. So at the 6th step, you know almost all letters in each word (some green, some yellow)! If you get all 5, think of the possible combinations, the greens will help to eliminate some of those options.
If you sre still short of letters for some words, start thinking of duplicate (may be triplicate!) use of one or more of the identified letters or the left-out letters Z, J, Q.
Using these, I have been able to solve almost 98% of all Octordle. Remaining 2% would not arise if a 14th move was allowed! This, without ever using VIXEN.
Most of those failures were due to choice of wrong options – if you get A, L in yellow and TER in green, is it ALTER or LATER (risk of losing one move)?
Btw, another such set of words are SPAWN, GUMBO, HYRAX, FLICK, VELDT (in any order) which also misses Z, J, Q and duplicates use of A and L.
Another approach could be to use ALERT, DISCO, and then NYMPH which cover all 15 most frequent letters except U. You are now left with 10 moves to find the 8 words. After inserting the first two, I look at all 8 blocks to see how they stand and sometimes you may be able to guess right maybe half of those, and inserting those will provide additional clues and you may be able to solve Quordle in 10 steps!
Hello Amit,
I am impressed. Thanks for sharing this information.
I have never played Octordle or Sedecordle. Sounds complicated. Do you know how big the following is for these games?
Charles
I would use LATER as opposed to ALTER, given your comment that A is usually in 2nd or 3rd position.
I’ve used NOISY + HATED + GRUMP + FLECK/FLACK/FLOCK.
Also ROUND + HEATS + CLIMB + GAWKY.
I like to use a word with a Y at the end; very informative.
Average Octordle score: 62.5.
One more thing:
I’d use PUDGY instead of FUDGY as the P is more common than the F.
I think
“Figure 2 includes multiple occurrences…”
should read
“Figure 3 includes multiple occurrences…”
(didn’t check to see of anyone has already noted this)
Hi Frank,
Thanks for catching this error. Actually, I think that “Figure 2” should be replaced by “Figure 1”. Figure 3 is like Figure 1 except that repeated letters are only counted once.
I appreciate your help in improving the accuracy of the Real Statistics website.
Charles
Hi from the UK!
I find using ADIEU or sometimes AUDIO for guess #1 and sometimes try to get the remaining vowel in the second guess.
After 510 games I have a 96% strike rate, not sure how this compares with others.
I’ve got the answer in 2 guesses 16 times, in 3 attempts 107 times but usually get it by 4th (190)
Hi Marc,
Your results seem pretty close to the optimum, but there is room for improvement.
If by a 96% strike rate you mean winning within 6 tries 96% of the time, then you should know that the strategy we used wins within 5 tries 100% of the time. You got the target within 2 guesses 3.15% of the time. You could boost this up to 6.48%.
Charles
Hi Marc,
I also have 96%, and have always started with AUDIO, but I have started to look at a different strategy now:
Avoiding the traps. What makes me fail, is if I end up in a trap, having three or four greens and more options then remaining tries. For example *IGHT has 9 legal words.
So, based on the frequency of the letters in the traps, I will avoid EASTORY in the beginning. The most frequent letters remaining are LUCID, so that is my new starting word.
My four words with 19 of the top 20 letters (I have #21, W, instead of #20, K):
CANES
WORTH
BLIMP
FUDGY
Hey, they work for me.
Dan,
Thanks for the feedback.
Charles
How about the following?
CAKES
NORTH
BLIMP
FUDGY
Charles
If you had to pick 4 words to maximize the probability of being able to solve a word, which 4 would you pick? I ask this because I often play Octordle which is 8 wordles at the same time in 13 guesses, so you want a to get all the common letters in there in their common spots and solving one at a time doesn’t work.
My not optimal current words are
Party
Blink
Mouch
Feeds
After reading your analysis I was looking to get a ‘G’ in there and maybe remove an E.
Also if I were to keep the double E, I should try to get them in the 4th and 5th position.
Thank you!
Hi Jared,
I can see that you are trying to use all the top 20 letters without repetition. I wasn’t able to find a better solution in the 10 minutes that I devoted to the task, but perhaps the word FORGE would be useful. This would work if MUCHS were a word to replace MOUCH. In any case, perhaps you can do something with this.
Charles
I have used the following 4-word sets on Octordle:
NOISY + HATED + GRUMP + FLECK/FLACK/FLOCK
ROUND + HEATS + CLIMB + GAWKY
However, I now always try to complete the puzzle using only three starter words, and I try to squeeze a few in after 2. The goal is 60 or under (a bit like golf …).
I am experimenting now with one suggestion in the article: LATER + SCION + PUDGY. I changed FUDGY to PUDGY as the P is more common.
John, my goal is to win the game and I usually do it in four.
My strategy is to get the vowels out and use three different words containing 15 different letters. I dislike uncommon words that are seldom used. Just a personal preference I guess.
My first word is aeons, which contains three vowels.
This gives me valuable information. If I have 0 or 1 vowel, my second word is build and the third crypt.
If I have 2 or 3 vowels, I place more emphasis on consonants. My second word is lymph and the third trick.
Quite often at this point I have determined 4 letters, sometimes 1 or 2 are green. Occasionally I get lucky and the winning word seems obvious. I then abandon the formula and go for the gold. Suppose the winning word is snare. I would then have four yellow letters after using aeons. I would then think that the word probably starts with s and ends with e. If sn, then the third letter must be a. I am missing the r!
I am always open to new ideas and would welcome and comments or suggestions you might have.
Regards,
John,
Thanks for sharing this.
Charles
Charles,
You may be happy to hear that I’ve seen the light.
For one thing always entering SLATE + IRONY was hardly more challenging or interesting than entering SLATE followed by a second guess from your list. The sole advantage of always using IRONY was that I could claim that it was something I thought of myself.
The main point , however, is that I’ve come to realize that always using the same first two guesses is a pretty poor idea. Instead the second guess has to take into account the information provided by the results of the first guess. This is well illustrated by the terminal Y in IRONY. I think that it makes good sense provided that the first guess does not reveal a terminal E (as Y is relatively common and almost always occurs in the last position). But it makes no sense at all if the first guess does reveal a terminal E, as in this case Y occurs in at most one of the remaining possible words.
I see how the probability of solving in 3 is equal to N/W, where W is the number of words remaining after the first guess and N is the number of patterns that might be returned by the second guess. The probability of winning in 3 is therefore maximized by minimizing W and maximizing N. How about using RAISE as the first guess? I’ve read that it minimizes the average value of W, and its worst case (*****) behavior is certainly significantly better than that of SLATE (W = 165 rather than W = 221).
If all one cares about is maximizing the probability of winning in 3 tries, it doesn’t matter how the W words are spread over the N patterns, but this matters a lot if one is interested in minimizing the average number of guesses to solve, or in avoiding the possibility of not solving at all. Take today (POWER) as an example. SLATE left 165 words on the table (not a great start!) but I was encouraged by the fact that DINER was going to spread these words over 63 patterns. I’d have a 0.38 probability of solving in 3, and on average I’d be left with just 2.6 words to deal with. But in the event I was left with 29 words, and they included a lot of those nasty “ryhming words” (mover, cover, rover, etc.) that can eat up guesses in a hurry. Happily I got a bit lucky and solved in 4, but I would have preferred a second guess may have produced fewer possible patterns (and hence a lower probability of solving in 3) but that also reduced the maximum number of words per pattern.
Might it be possible to produce a set of second guesses that is rather more tailored to avoiding the worst case by using a somewhat different objective function (one that both takes into account the value of increasing N and the desirability of spreading the W words as evenly as possible over the N patterns)?
Regards – John
Hi John,
It looks like our thinking about Wordle is converging.
“raise” seems to be an excellent first guess. The probability of winning within 3 tries is 55.8%, which is not far from “slate”. It is possible that the average number of tries to winning is better. I have not tried to solve this problem yet. I was starting to investigate the best moves to win within 4 tries, but I got distracted by other things before I obtained a solution.
Charles
Charles,
To say that our thinking is converging rather flatters my contribution. I think its more a case of my ignorance being overwhelmed by your insight.
I think I can now quantify what I’m getting at, and today’s WORDLE (spoiler alert) provides a good example. SLATE returned G**Y*, leaving 39 possible words. At this point your table called for me to use CHUNK as my next guess, but after looking at the letter frequency for the remaining words I chose to use FRONT instead. This left me with 5 possible words (STOOP,STOCK,STOMP,STOIC, STOOD) and a choice between using CRIMP as a test word (guaranteed solution in 4) or taking a chance on STOOP (1/5 chance of solving in 3, 3/5 chance of solving in 4, and 1/5 chance of solving in 5). As the average number of guesses was the same, I went with STOOP and solved in 4. After the fact I investigated the relative merits of CHUNK and FRONT. CHUNK produces 19 possible patterns versus 15 for FRONT and so gives both i) a higher probability of solving in 3 and ii) a lower number of words per pattern (i.e. on average, one will be left with fewer remaining words). But CHUNK might leave one with 9 remaining words (and this would have happened today) while FRONT will never leave one with more than 5. So unless there’s a test word that will distinguish between SPORT,STIFF,STOMP,STORY,STORM,STRIP,SWIFT,STOOD, and STOOP (an interesting little WORDLE problem) CHUNK does not guarantee a solution in 4, whereas FRONT probably does (I’d have to check that there are test words for all of the 6 other patterns that leave more than 2 possible words).
Can I suggest that you modify your table of second guesses so that it includes the worst case number of words remaining? It’s not something I need now that I have the means of working it out, but this information might be of interest to others.
And I would really like to see a second table that gives, for each possible pattern, the second guess that minimizes the worst case number of remaining words (with the pattern count used as a tie breaker). There may well be, for example, a guess that is even better than FRONT in this regard.
Regards – John
P.S. I don’t know how you broke ties in compiling the existing table, but I’d suggest that the worst case number of remaining words would be a good choice.
Oops – I wasn’t thinking. The average number of words left after a guess isn’t inversely proportional to the number of possible patterns. This is because patterns that correspond to a larger number of words are more probable. Using FRONT rather than CHUNK gives one both a lower average number of words (3.410 vs 3.872) and a lower worst case number of words (5 vs 9). CHUNK is better only in that it gives a somewhat higher probability of solving in 3. Elsewhere in the table DONER is much better than DINER after ****Y if one’s figure of merit is the average number of words (7.218 vs 8.152) or the worst case number of words (20 vs 29), though the lower number of patterns (56 vs 63) does mean that one has a lower probability of solving in 3.
So now we have three possible ways of evaluating possible second guesses. One can maximize the number of patterns (the probability of solving in 3), minimize the average number of words remaining, or minimize the worst case number of words remaining.
Hi John,
Regarding (1) Maximizing the number of patterns (the probability of solving in 3), (2) Minimizing the average number of words remaining, or (3) minimizing the worst case number of words. I assume that by (2), you mean the average number of tries to guessing the target word.
As a first step, I am thinking about providing the following info for any second guess:
(1) Number of patterns, (2) average number of tries to victory, and (3) worst case number of tries to victory.
Charles
Hi John,
I expect to add some more information about Wordle to the website as well as to the software to address some of the issues that you have raised. Thanks for all your comments. It has been very helpful to me.
Charles
From your WORDLE word choices, it appears you are playing in Easy mode. Hard mood requires that in subsequent words Green letters must appear in the same place it appears in previous words, and Yellow letters must appear in subsequent words but may be used in any place in the word. I would really like to see an algorithm for that mode.
If you want more of a challenge use a different word each day of the month, never repeating the same first word within the month. This approach slightly increases the importance of a good second word, especially in hard mood. I would like to see a list of the best second words.
A friend plays the same first word as me each day. We make a list of 28 to 32 words each month, using a category to restrict the words that can be selected as first words. For example, one month’s list was restricted to words appearing in the titles of the top 100 songs (according to Billboard and Official Charts as shown on Wikipedia) released in a certain year. Another month we used words appearing in Beatles lyrics.
Over 290 WORDLES I have an average solve rate of 3.75, using this method of choosing first words, with one failure to solve. My friend has an average of about 4.0 with no failures to solve. Of course, the choice of the best second word is crucial with this approach. According to an article in NYT, the average number of words to solve among those choosing to have NYT accounts (free to $1.50/month and up) and giving permission to be included, is about 3.8. They developed an algorithm for solving in the minimum number of turns. It has an average 3.4. It is called WORDLE-Bot. https://www.nytimes.com/interactive/2022/upshot/wordle-bot.html
It uses LEAST as its first word. This is based on its evaluation of which words are most likely to be a solution comparing words that have already appeared as solutions compared to its list of the most common five-letter words in English. It uses a solving method almost identical to the approach(es) described here.
Well done. And keep up the good work, perhaps using my suggestions for further analysis.
John,
1. Looks like you are making great progress with your analysis. It seems to me that coming up with guesses that minimize the average number of tries is a harder problem than guesses that maximize the probability of victory in 3 turns. As I said in an earlier response, I know how to maximize the probability of victory in 4 turns, but I haven’t had the energy to complete the implementation.
2. I have an idea about providing a partial solution to the issue of the average number of tries. I’ll look into this.
3. I’ll also look into your suggestion about modifying the table of second guesses so that it includes the worst case number of words remaining.
4. I break ties simply by choosing the alternative lowest in alphabetic order. If I solve #3, it will be easy to pick the alternative with the lowest worst case.
Charles
Charles,
I was thinking of average number of words as the expected number of words remaining after the guess. This is easily calculated as [sum Pi * Wi ] = [sum Wi^2 / W] /, where W is the total number of words remaining prior to the guess, Wi is the number of words associated with the ith pattern, and Pi is the probability of this pattern occurring (Wi/W). And the maximum number of words remaining after the guess is simply max(Wi). Working out the average and maximum number of tries required to solve is an altogether more challenging problem, and I’m not sure that this information would add all that much. Intuitively the average number of guesses will tend to follow the average number of words remaining, and the maximum number of tries required to solve is connected to the maximum possible number of words remaining.
One complication is that the number of words remaining doesn’t correlate directly to the number of guesses required. 1 word remaining does give (avg = 1, max = 1) and 2 words (avg = 1.5, max = 2), but 3 words remaining can mean (avg = 2, max = 4) or (avg =1.67, max = 2) or (avg = 2, max = 2) depending upon i) whether the information provided by guessing one of the words is enough to distinguish between the other two possibilities and ii) whether the next guess is used as a test rather than an attempt at a solution.
I’ve switched to using RAISE, in part so that I have to depend upon my own guesses rather than relying on your table. I am, however, beginning to have my doubts. It turns out that the superior first round performance of RAISE (an average of 61 words left vs 71.57 for SLATE, a worst case of 165 words left vs 221 for SLATE) is due entirely to the ***** and ****Y patterns. Knock these out and SLATE looks better. And the ***** pattern with SLATE isn’t really the weak point that it might appears too be. Guessing ROUND takers one down to an average of just 6.412 words remaining, and one is guaranteed that there will be no more than 14 words left. By comparison RAISE + MULCH (the best second guess that I’ve been able to come up with) leaves an average of 6.857 words, and up to 16 words may remain. RAISE + MULCH does give a slightly higher probability of solving in 3 (.357 vs .326) but clearly SLATE recovers to a position of near equality after two rounds. The *****Y situation is a bit more nuanced, and I continue to think that DINER is a poor second choice because both the average and maximum number of remaining words are so high (I now lean to NIDOR, which gives 58 patterns, an average of 6.62 remaining words, and a maximum of 17 remaining words), but SLATE does at least come out on top when it comes to the probability of winning in 3.
I’ve now modified my spreadsheet so that I can enter possible guess words and have it tell me i) the number of possible patterns, ii) the average number of words remaining, and iii) the maximum number of words remaining. Playing around with this allows me to avoid really bad guesses, come up with semi-optimal guesses, and test your suggested choices to see how well they stack up in terms of the average and maximum number of words remaining. It’s been interesting, and cramming as many as possible of the letters that occur most frequently in the remaining words into a guess is certainly no guarantee that one will achieve anything useful. Often tossing in a less frequent letter will magically improve things.
– John
The fact that the word GEESE has three E’s in it serves to make E more “frequent”, but does nothing to increase that a probability that a guess word with a single E in it will produce a hit. I’d be interested in knowing the fraction of Wordle words that contain an E, the fraction of words that contain an A, and so on. This approach would produce somewhat different results in that letters that are frequently doubled would become less common, and letters that are rarely doubled would become less so.
Hi John,
Good point. I have just added a new letter frequency table to the webpage (see the new Figure 3).
Charles
Thanks. This does change things a bit (e.g. C drops from being the 10th most common letter to being the 11th, and U moves up one spot). If the initial two guesses are to cover the ten most likely letters they must include all of EAROTLISUN (e.g. AROSE + UNLIT is one possibility). One plus to this strategy is that after the first two guesses the vowel situation will be known (save for the possibility of duplicates and Y). Personally I think that this is the way to go. If testing for the most common letters produces lots of hits (as might reasonably be expected) one will be left in good shape, and if there are two or less hits this is in fact also good news. Being able to eliminate all words containing common letters narrows things down a lot.
John,
It turns out that letter frequency is less important than pattern frequency. This is explained elsewhere on the website.
Charles
Ah, but where’s the fun in simply manually implementing what is essentially a computer generated solution? I’m looking for a strategy that is within my abilities.
Another objection to a letter frequency approach is that it assumes that words are randomly chosen from the list of possible words. I’m not sure that this is the case, and have a hunch that words with lots of common letters are less likely to be chosen. They’re on to me!
Hi John,
I understand. My insight was to recognize that pattern frequency was better than letter frequency. Once I understood that the rest was, as you have said, a computer-generated solution.
Charles
This has been shown to be incorrect.
It is better to go by the total amount of times a letter appears in all words.
I know it’s been 2½ years since you wrote this.
Recap: It is better to go by EAROT LISNC, where C is in the top-10 due to a fraction of the Solutions having a couple of double-C words CLOCK, CHECK, CACAO COCOA; vs having the U in the top 10 when you remove the repeat Cs.
The correct top-10 is EAROT LISNC.
You have (EARIT OLSNU) with a downgraded O, and downgraded C. And an upgraded I & U.
There is value in having the O & C properly in top-5 and top-10 respectively. This does mathematically increase your odds of hitting a green O and/or C vs having the I & U elevated.
This is heuristically proven. When using a Decision Tree to find the best possible average score for any given starting word, words with O & C have better averages than words with I & U.
C vs U
C-words CRATE, CARLE, TRACE, CRANE CARNE are all in the top-10 (Default Mode) for best average score. Ranging from 3.41xx to 3.42xx
The 1st word with a U anywhere in it is SAULT at 74th, and then TRUCE at 95th.
Source:
https://github.com/alex1770/wordle/blob/main/results_easy_nyt20220830
O vs I
1st three O-words:
TORSE, TRONE, ROAST
12th, 23rd, 24th
1st three I-words
TRICE, TRINE, TIARE
16th, 18th, 26th
Even if this 2nd part wasn’t true, the 1st part still is.
There are simply more Cs than Us. And there are simply more Os than Is. Using those letters in your 1st two guesses will yield better results.
In fact, one of the absolute most efficient two-word fixed opening pairs is SOARE-CLINT.
Followed by several anagrams of SOARE-CLINT.
Exactly 100 out of the top 100 pairs have a C in the opening two words. Ranging from 3.595 to 3.6241
Only *TWO* out of the top-100 two-word opening sets has a U in it.
#47 CARLE-SUINT (3.6172 average score)
#64 CRINE-SAULT (3.6206 average score)
To find a pair with a U and WITHOUT a C, I had to dive all the way down to 578th! PARLE-SUINT, with an average score of 3.6418.
Bottom line, every way you analyze this, it’s better to go by how many total times a letter appears. The 3 Es in GEESE makes a difference. The two Os in TROOP and CROOK makes a difference. The two Cs in CHECK, CLOCK, and COCKY make a difference.