Basic Concepts
We will assume an ARMA(p, q) process with zero mean
![]()
We will further assume that the random column vector Y = [y1 y2 ··· yn]T is normally distributed with pdf f(Y; β, σ2) where β = [φ1 ··· φp θ1 ··· θq]T. For any time series y1, y2, …, yn the likelihood function is
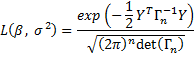
where Γn is the autocovariance matrix. As usual, we treat y1, y2, …, yn as fixed and seek estimates for β and σ2 that maximizes L, or equivalently the log of L, namely
![]()
This produces the maximum likelihood estimate (MLE) B, s2 for the parameters β, σ2. Equivalently, our goal is to minimize
![]()
Properties
Property 1: For large enough values of n, 

![]()
Observation: From Property 1, we can conclude that for large enough n, the following holds, where the parameter with a hat is the maximum likelihood estimate of the corresponding parameter.
| AR(1) | |
| AR(2) | |
| MA(1) | |
| MA(2) | |
| ARMA(1,1) |
It turns out that -2LL can be expressed as
![]()
Thus to minimize -2LL, we need to minimize
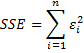
We show how to do this in Calculating ARMA Coefficients using Solver.
References
Greene, W. H. (2002) Econometric analysis. 5th Ed. Prentice-Hall
https://www.ctanujit.org/uploads/2/5/3/9/25393293/_econometric_analysis_by_greence.pdf
Gujarati, D. & Porter, D. (2009) Basic econometrics. 5th Ed. McGraw Hill
http://www.uop.edu.pk/ocontents/gujarati_book.pdf
Hamilton, J. D. (1994) Time series analysis. Princeton University Press
https://press.princeton.edu/books/hardcover/9780691042893/time-series-analysis
Wooldridge, J. M. (2009) Introductory econometrics, a modern approach. 5th Ed. South-Western, Cegage Learning
https://cbpbu.ac.in/userfiles/file/2020/STUDY_MAT/ECO/2.pdf
Dear Charles,
Will ARIMA be useful to apply in software project data to find out correlation among the employee skillset and availability so that we can take decision to assign the task.
I don’t know whether ARIMA could be used in this context.
Charles
Just for the clarity of things and consistency in notation you should use lower case “ln” for the natural logarithm below the box showing the distribution properties.
Bill,
Yes, you are correct. I just updated the webpage as you have suggested.
Thanks for catching this.
Charles
How would the procedure be if I want to estimate the parameters, with the Newton-Raphson method?
Antony,
I haven’t tried doing it that way, but I will eventually look into this.
Charles
ok
informative annex on the subject:
http://www.ru.ac.bd/stat/wp-content/uploads/sites/25/2019/03/504_02_Hamilton_Time-Series-Analysis.pdf
The wilks lambda statistic for factor b and iteration still give different results
Antony,
I am reporting Wilks Lambda raised to the 1/b power where b is as described at
https://www.real-statistics.com/multivariate-statistics/multivariate-analysis-of-variance-manova/two-way-manova/
Thus, for the row value (factor a), Wilks Lambda is the value that I reported in the example on the webpage since b = 1.
For the column value (factor b), Wilks Lambda is the square of the value that I reported since b = 2. Thus Wilks Lambda is, therefore, .504 (the square root of this is .710, which is the value that I reported).
The situation is similar for the interaction (factor ab) where b = 2, and so Wilks Lambda = .387.
Does this agree with the values you got?
Charles
Antony,
Thanks for sending me this link.
Charles
thanks for the clarification doctor
Dear Charles,
If we arrive at the criterion of minimizing the squared residuals, why do people fuss so much about ‘maximizing likelihood’?
Another question, is there a formula for the general terms in the autocovariance matrix for orders higher than AR(1)?
Thanks,
O.
Dear Otavio,
In many cases, minimizing the the sum of the squared residuals is equivalent to maximizing the likelihood.
There are some formulas for the autocovariance matrix, especially for AR(1) and AR(2). See
Basic Concepts of AR(p) Processes
Charles