The Real Statistics Resource Pack provides support for the proportional odds model of ordinal regression using Newton’s method, as described in Proportional Odds Model.
Worksheet Functions
Real Statistics Functions: The Real Statistics Resource Pack provides the following array function where R1 contains data in either raw or summary form.
OLogitCoeff(R1, r, lab, head, alpha, iter, guess) – calculates the ordinal regression coefficients using Newton’s method for the data in R1. For each coefficient, the output also includes the standard error, Wald statistic, p-value, and 1 – α confidence interval. If head = TRUE then R1 includes column headings.
For each row in R1, the initial n columns specify values for the independent variables. If r = 0, then R1 is in raw data format with n+1 columns where the last column of R1 contains category numbers (integer values starting with 1); otherwise, R1 is in summary format and contains n+r columns where the last r columns specify the counts for each category 1, 2, …, r.
The output specifies the coefficients. If there are r categories, then the first r-1 entries specify the coefficients a1, …, ar-1, and the remaining n entries specify the coefficients b1, …, bn. If guess is included then the coefficients in the n+r-1 × 1 column array guess are used as the initial values in Newton’s method; if this argument is omitted then the function decides internally what initial values to use.
alpha specifies the significance level (default .05) and iter (default 20) specifies the number of iterations used by Newton’s method.
Related worksheet functions
The Real Statistics Resource Pack also provides the following array functions where R1 contains data in either raw or summary form and Rc is a column array that contains the ordinal regression coefficients, where R1, Rc, and r are as described above. We will assume that there are n independent variables and r categories 1, 2, …, r (and so Rc has n+r-1 rows).
OLogitCov(R1, Rc, r) – returns the covariance matrix corresponding to the regression coefficients in Rc based on the data in R1.
OLogitConverge(R1, Rc, r) – returns the F column array described in Property 2 of Proportional Odds Model. The values in this array should all be close to zero if Rc provides a sufficiently accurate representation of the ordinal regression coefficients. Note that if B adequately represents the true regression coefficients and C represents the covariance matrix for these coefficients (e.g. as calculated by OLogitCov) then per Property 2 of Proportional Odds Model, B – CF should be very close to zero.
OLogitLL(R1, Rc, r, lab) – returns a column array with the values LL, LL0, chi-square test results (chi-square stat, df, and p-value), R-square (McFadden, Cox and Snell, Nagelkerke versions), AIC and BIC. If lab = TRUE (default FALSE) then an extra column is appended to the output which contains labels.
The Real Statistics Resource Pack provides the following non-array function:
OLogitCorrect(R1, Rc, r) = the fraction of the observations in R1 for which the ordinal regression model based on the coefficients in Rc correctly predicts the observed outcome (i.e. where the observed category is the one with the highest probability per the model)
The Real Statistics Resource Pack also provides the following array functions:
OLogitSummary(R1, head) – array function that takes the raw data in R1 and outputs an equivalent array in summary form. If head = TRUE then R1 includes column headings as well as the output.
OLogitPredC(R0, Rc) – outputs an m × r array corresponding to the m × n array R0. Each row in the output contains the probability for each of the r categories based on values of the n independent variables in the corresponding row of R0 based on the regression coefficients in Rc.
OLogitPredX(R0, Rc) – outputs a 1 × r array listing the probabilities of outcomes 1, …, r, where r = 1 + the number of columns in Rc, for the values of the independent variables contained in the range R0 (in the form of either a row or column vector). If R0 is a 1 × k row vector or k × 1 column vector, then Rc is a (k+1) × (r-1) range.
Data Analysis Tool
Real Statistics Data Analysis Tool: The Real Statistics Resource Pack supplies an Ordinal Regression data analysis tool that builds an ordinal regression model for data in raw or summary format.
We now show how to use this tool to build the model for Example 1 of Ordinal Regression Basic Concepts (where the summary data is replicated on the left side of Figure 1).
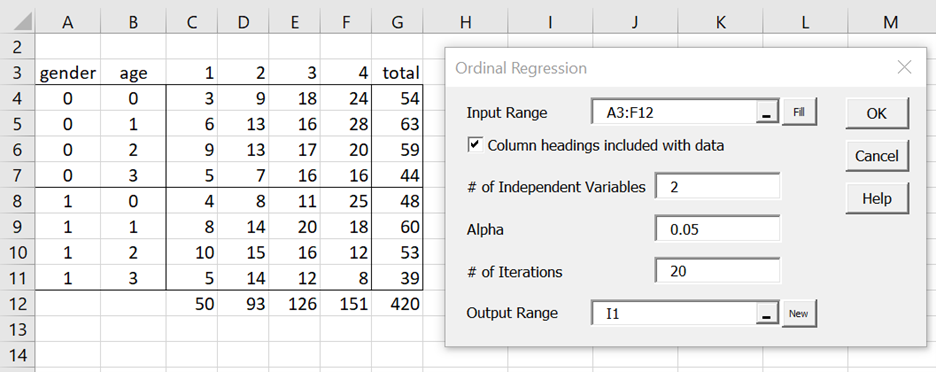
Figure 1 – Ordinal Regression dialog box
Press Ctrl-m and choose the Ordinal Regression option from the Reg tab (or from the Regression dialog box if using the older user interface). Now, fill in the dialog box as shown on the right side of Figure 1. After pressing the OK button, the output shown in Figures 2 and 3 is displayed.
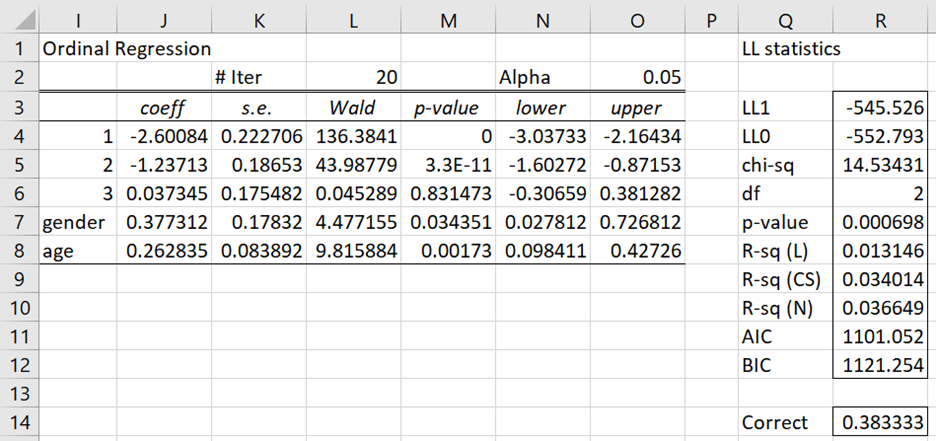
Figure 2 – Ordinal regression results (part 1)
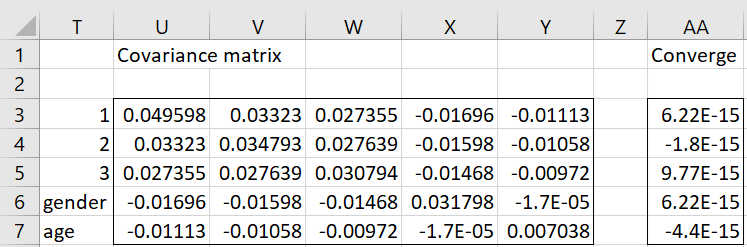
Figure 3 – Ordinal regression results (part 2)
The values near zero in column AA show that Newton’s method converged to a solution. The p-value of .0007 in cell R7 shows that the model is significantly different from the model without independent variables.
We see that this model predicts correctly 38.3% of the 420 observations; i.e. the observed category had the highest predicted probability 38.3% of the time (as opposed to ¼ = 25% based on pure chance).
The formulas shown in Figure 4 were used to produce the output in Figures 2 and 3.
| Output | Range | Formula |
| Coefficients | I3:O8 | =OLogitCoeff(A3:F11,4,TRUE,TRUE,O2,L2) |
| LL and related statistics | Q3:R12 | =OlogitLL(A4:F11,J4:J8,4,TRUE) |
| Proportion correct | R14 | =OlogitCorrect(A4:F11,J4:J8,4) |
| Covariance matrix | U3:Y7 | =OlogitCov(A4:F11,J4:J8,4) |
| Convergence vector | AA3:AA7 | =OlogitConverge(A4:F11,J4:J8,4) |
Figure 4 – Key formulas
Raw Data Format
We can perform a similar analysis for data in raw format. When data is in raw format, then we have two choices. The first of these choices is to use the OLogitSummary array function to convert the data from raw format to summary format and then use the Ordinal Regression data analysis tool, using the summary data as input, as described above.
E.g. to convert the raw data in range A3:C13 of Figure 5 to summary format, we can use the array formula =OLogitSummary(A3:C13,TRUE), whose output is shown on the right side of Figure 5.
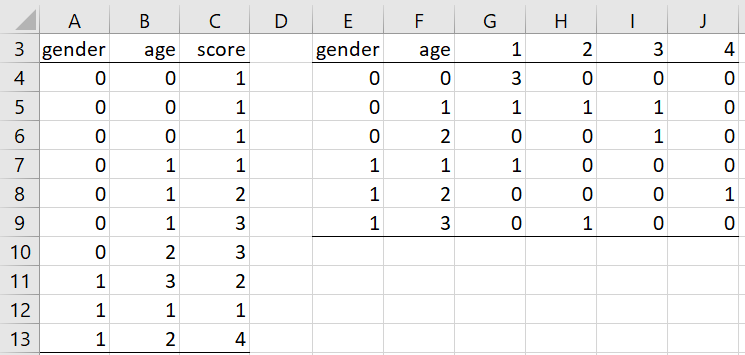
Figure 5 – Convert raw data to summary format
The other approach is to use the Ordinal Regression data analysis tool directly, using the raw data as input. Assuming that the data on the left side of Figure 5 represents only the first 10 of 420 rows of data equivalent to the summary data for Example 1 shown on the left side of Figure 1, we would follow the procedure described above, except that we would instead insert the range A3:C423 (from Figure 5, where the remaining 410 rows are not displayed) in the Input Range field of the dialog box shown in Figure 1. When the OK button is pressed, the output would be identical to that shown in Figures 2 and 3.
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
References
Agresti, A. (2013) Modeling Ordinal Categorical Data tutorial
http://statmath.wu.ac.at/research/talks/resources/slidesagresti_ordinal.pdf
Hyun Sun Kim (2004) Topics in ordinal logistic regression and its applications. Dissertation Texas A & M
No longer accessible online
I am surprised and I love the Analysis Toolpak. It’s so aswesome. I just wanna know if it’s possible you can add an option for plotting control charts and other control quality tools in a next update of your add-in. Even, violin plot and swarmplot.
Thanks a lot!
Hello Carlos,
I am pleased that you are getting value from the Real Statistics resource pack.
I will add violin and swarm plots to my list of possible future enhancements.
Currently, the resource pack provides boxplots, dot plots, and KDE plots.
Charles
Thank you for digging up the references. I looked through and the second article in particular is making me rethink both my binomial and ordinal residual bootstrap procedure.
I’m now testing a somewhat empirical approach and fit many leave-N-observations-out model combinations to obtain a distribution of regression coefficients, which I then apply to my full observation set to estimate accuracy. I leave out ~20% of the observations each time.
Appreciate if you have further feedback, and thanks again!
Glad I could help.
I am thinking of adding bootstrapping for binomial logistic regression to Real Statistics.
Charles
Dr. Zaiontz,
First, thank you for your this open resource, it helps tremendously with my work.
My question will be about bootstrapping ordinal multinomial logistic regression (oMLR) models using residuals. To begin, I have prior experience with bootstrapping to obtain robust estimators for binomial logistic regression – randomly sampling from the residuals (n-by-1 vector) and adding them to the original response variable seemed straightforward. But, with oMLR I have a residual matrix.
Briefly about my data, I have a categorial response variable with three ordinal levels coding the change in patellar tendon morphology between two timepoints (-1: better, 0: same, 1: worse). My predictors are continuous variables like the change in land-jump hip/knee joint angles and joint torques.
I am using MATLAB’s statistics toolbox, and when I fit oMLR it provides me with a n-by-2 matrix of residuals which I understand how they’re calculated. My question is: How do I then use the two values in each row of the residual matrix with my original Y and generate a new pi* and Y* for iterative resampling?
Thank you!
Andrew k.
Below is a subset of four observations from my dataset showing probability estimates (pihat) for each category, the predicted category (pred), original response (Y), and residuals (resid1 resid2). I need help properly combining resid1 and resid2 with Y to get pi* and subsequently Y*. I hope the row and column text alignment is preserved so it’s clear.
pihat pi*
-1 0 1 pred Y resid1 resid2 -1 0 1 Y*
0.024 0.681 0.296 0 0 -0.024 0.296 ? ? ? ?
0.004 0.278 0.718 1 1 -0.004 -0.282 ? ? ? ?
0.196 0.764 0.040 0 -1 0.804 0.040 ? ? ? ?
0.575 0.418 0.008 -1 -1 0.425 0.008 ? ? ? ?
Hi Andrew,
So that I can understand the context of your comment, why do you want to use bootstrapping for oMLR?
Charles
Hi Charles,
The dataset is not very big with 36 observations and the group sizes are not equal: N(better)=5, N(same)= 24, and N(worse)=7; also, I have 3 predictor variables. Mainly because of group size heterogeneity I felt it would be a good idea to test the robustness of the estimators through bootstrap.
-Andrew K.
Hi Andrew,
Thanks for the clarification. I have not implemented bootstrapping for ordinal regression. The following papers about bootstrapping for logistic regression may be helpful:
https://www.scirp.org/journal/paperinformation.aspx?paperid=70962
http://faculty.washington.edu/yenchic/17Sp_403/Lec6-bootstrap_reg.pdf
There is also this paper specifically about ordinal regression, but it is not written in English.
https://jurnal.unej.ac.id/index.php/JID/article/view/130/100
Charles