Overview
We describe how to find the regression coefficients for the proportional odds model of ordinal regression (as described in Ordinal Regression Basic Concepts) using Newton’s method.
Suppose the possible outcomes for the dependent variable are 1, …, r. Let pih = P(yi ≤ h), i.e. the cumulative probabilities. Thus 0 = pi0 < pi1 ⋯ < pir = 1 (thereby capturing the order of the outcomes), where pi0 = 0 for notational convenience. Then for h = 1, …, r
P(yi = h) = P(yi ≤ h) – P(yi ≤ h–1) = pih – pih-1
For the proportional odds model where the data {X1, X2, …, Xn} is a set of k-tuples Xi = (xij: j = 1 to k), we define the regression model
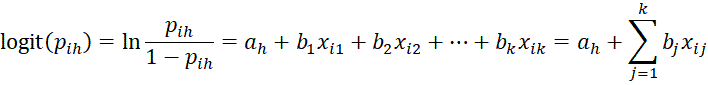
for each value of h = 1, …, r-1 and where for convenience we set xi0 = 1. As explained in Ordinal Regression Basic Concepts, for each ordinal category h we use a separate intercept coefficient ah but the same slope coefficients bj.
Note too that a1 < a2 … < ar-1. We also see that
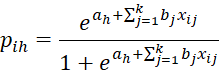
Log-Likelihood Function
Our goal is to find the values of the regression coefficients a1, … ar-1, b1, … bk that maximize the log-likelihood function
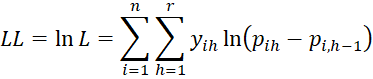
Property 1: The maximum value of the log-likelihood function LL occurs when the following r+k-1 equations hold for h = 1 to r-1.
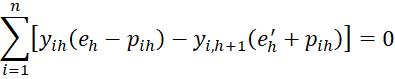
or alternatively
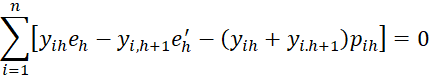 and for j = 1 to k
and for j = 1 to k
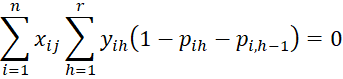
where
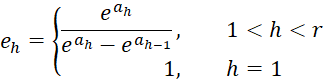
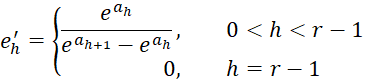
Proof: click here
Newton’s Method
Property 2
Let
![]()
![]()
where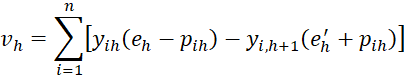
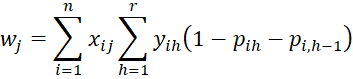
and J is the k+r-1 × k+r-1 symmetric matrix of form
![]()
where C = [chl] is an r-1 x r-1 matrix, D = [djg] is a k × k matrix and U = [ujh] is an k × r-1 matrix consisting of the following elements
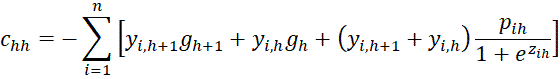
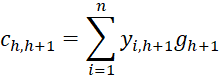
![]()
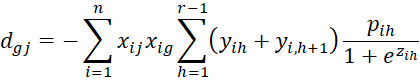
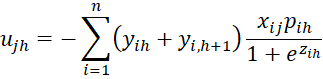
where
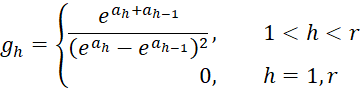
Then
B* = B – J-1
is a better estimate of the coefficients than B (i.e. it produces a larger value for LL), and so the sequence B, B*, B**, B***, etc. converges to the coefficient vector that maximizes LL and the corresponding Hessian matrix J-1 is a good estimate of the covariance matrix for the regression coefficients.
Proof: click here
Reference
Hyun Sun Kim (2004) Topics in ordinal logistic regression and its applications. Dissertation Texas A & M
No longer accessible online
Agresti, A. (2013) Modeling Ordinal Categorical Data tutorial
http://statmath.wu.ac.at/research/talks/resources/slidesagresti_ordinal.pdf
McCullagh, P. (1980) The proportional odds model
https://www.stat.uchicago.edu/~pmcc/reports/prop_odds.pdf