Basic Concepts
In order to use MANOVA the following assumptions must be met:
- Observations are randomly and independently sampled from the population
- Each dependent variable has an interval measurement
- Dependent variables are multivariate normally distributed within each group of the independent variables (which are categorical)
- The population covariance matrices of each group are equal (this is an extension of homogeneity of variances required for univariate ANOVA)
These assumptions are similar to those for Hotelling’s T-square test (see Hotelling’s T-square for Two samples). In particular, we test for multivariate normality and homogeneity of covariance matrices in a similar fashion.
Multivariate normality
If the samples are sufficiently large (say at least 20 elements for each dependent × independent variable combination), then the Multivariate Central Limit Theorem holds and we can assume the multivariate normality assumption holds. If not, we would need to check that the data (or residuals) for each group is multivariate normally distributed. Fortunately, as for Hotelling’s T-square test, MANOVA is not very sensitive to violations of multivariate normality provided there aren’t any (or at least many) outliers.
Univariate normality
We start by trying to show that the sample data for each combination of independent and dependent variables is (univariate) normally distributed (or at least symmetric). If there is a problem here, then the multivariate normality assumption may be violated (of course you may find that each variable is normally distributed but the random vectors are not multivariate normally distributed).
For Example 1 of Manova Basic Concepts, for each dependent variable we can use the Real Statistics ExtractCol function to extract the data for that variable by group and then use the Descriptive Statistics and Normality data analysis tool contained in the Real Statistics Resource Pack.
E.g. for the Water dependent variable (referring to Figure 1 of Manova Basic Concepts and Figure 3 of Real Statistics Manova Support), highlight the range F5:I13 and enter the array formula =ExtractCol(A3:D35,”water”). Then enter Ctrl-m and select Descriptive Statistics and Normality from the menu. When a dialog box appears, enter F5:I13 in the Input Range and chose the following options: Column headings included with data, Descriptive Statistics, Box Plot and Shapiro-Wilk and then click on OK. The resulting output is shown in Figure 1.
Univariate normality results
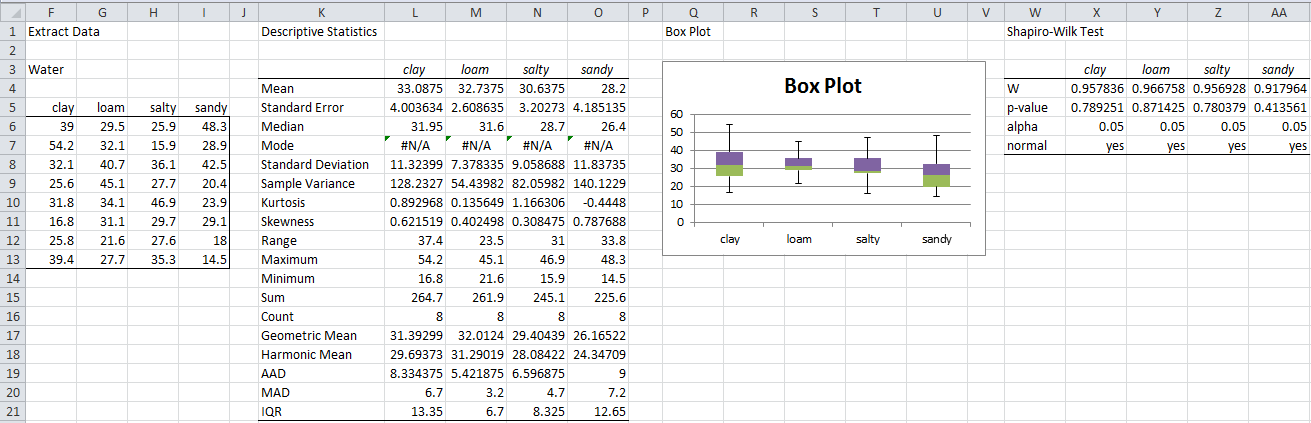
Figure 1 – Tests for Normality for Water
The descriptive statistics don’t show any extreme values for the kurtosis or skewness. We can see that the box plots are reasonably symmetric and there aren’t any prevalent outliers. Finally, the Shapiro-Wilk test shows that none of the samples shows a significant departure from normality.
The results are pretty similar for Yield. Also, the results for Herbicide show that the sample is normally distributed, but the box plot shows that there may be a potential outlier. The kurtosis value shown in the descriptive statistics for loam is 3.0578, which indicates a potential outlier. We return to this issue shortly.
QQ plots
We can also construct QQ plots for each of the 12 combinations of groups and dependent variables using the QQ Plot data analysis tool provided by the Real Statistics Resource Pack. For example, we generate the Water × Clay QQ plot as follows: press Ctrl-m, select the QQ Plot from the menu and then enter F6:F13 (from Figure 1) in the Input Range and click on OK. The chart that results, as displayed in Figure 2, shows a pretty good fit with the normal distribution assumption (i.e. the points lie close to the straight line).

Figure 2 – QQ plot Water × Clay
Multivariate normality
It is very difficult to show multivariate normality. One indicator is to construct scatter plots for the sample data for each pair of dependent variables. If the distribution is multivariate normal, the cross-sections in two dimensions should be in the form of an ellipse (or straight line in the extreme case). E.g. for Yield × Water, highlight the range B4:C35 and then select Insert > Charts|Scatter. The resulting chart is shown in Figure 3.

Figure 3 – Scatter plot for Yield × Water
To produce the scatter plot for Water × Herbicide, similarly highlight the range C4:D35 and select Insert > Charts|Scatter. The case of Yield × Herbicide is a bit more complicated: highlight the range B4:D35 (i.e. all three columns of data) and select Insert > Charts|Scatter as before. The resulting chart is shown in Figure 4.

Figure 4 – Scatter plots for Yield × Water and Yield × Herbicide
Series 1 (in blue) represents Yield × Water and series 2 (in red) represents Yield × Herbicide. Click on any of the points in series 1 and hit the Delete (or Backspace) key. This erases the blue series and only the desired red series remains. Adding the title and removing the legend produces the scatter chart in Figure 5.

Figure 5 – Scatter plot for Yield × Herbicide
All three scatter plots are reasonably elliptical, supporting the case for multivariate normality.
Outliers
As mentioned above, the multivariate normality assumption is sensitive to the presence of outliers. Here we need to be concerned with both univariate and multivariate outliers. If outliers are detected they can be dealt with in a fashion similar to the univariate case.
Univariate outliers
For the univariate case, generally we need to look at data elements with a z-score of more than 3 or less than -3 (or 2.5 for smaller samples, say less than 80 elements). For data that is normally distributed (which, of course, we are assuming is true of our data), the probability of a z-score of more than +3 or less than -3 is 2*(1–NORM.S.DIST(3, TRUE)) = 0.0027 (i.e. about 1 in 370). The probability of a z-score of more than 2.5 or less than -2.5 is 0.0124 (i.e. about 1 in 80).
The values 2.5 and 3.0 are somewhat arbitrary, and different estimates can be used instead. In any case, even if a data element can be classified as a potential outlier based on this criterion, it doesn’t mean that it should be thrown away. The data element may be perfectly reasonable (e.g. in a sample of say 1,000 elements, you would expect at least one potential outlier 1 – (1-.0027)1000 = 93.3% of the time.
Using Real Statistics capabilities
Since we suspect there is an outlier in the herbicide sample, we will concentrate on the data in that sample. We first use the Real Statistics array formula =ExtractCol(A3:D35,”herbicide”) to extract the herbicide data. We then look at the box plot and investigate the outliers for that sample using Real Statistics’ Descriptive Statistics and Normality data analysis tool as follows.
First, press Ctrl-m and select Descriptive Statistics and Normality from the Desc tab. Now, enter F33:I41 in the Input Range and choose the Column headings included with data, Box Plot and Outliers and Missing Data options. The output is shown in Figure 6.
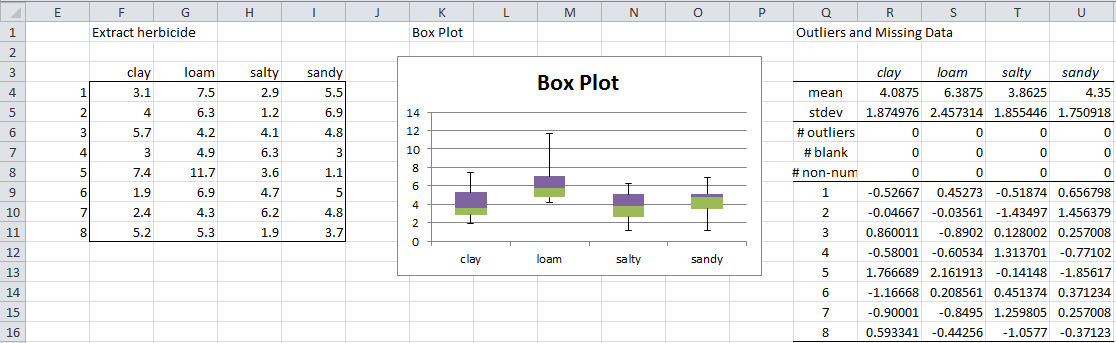
Figure 6 – Investigation of potential outliers in Herbicide data
Box plot and z-score
As mentioned previously, the Box Plot (see Figure 6) for herbicide in Example 1 of Manova Basic Concepts indicates a potential outlier, namely the data element in cell G38. The z-score for this entry is given by the formula (cell S13).
STANDARDIZE(G38,AVERAGE(G34,G41),STDEV(G34,G41)) = 2.16
This value is still less than 2.5, and so we aren’t too concerned. In fact, the report shows there are no potential outliers.
Multivariate outliers
Multivariate outliers are harder to spot graphically, and so we test for these using the Mahalanobis distance squared. For any data sample X with k dependent variables (here, X is an k × n matrix) with covariance matrix S, the Mahalanobis distance squared, D2, of any k × 1 column vector Y from the mean vector of X (i.e. the center of the hyper-ellipse) is given by
![]()
Since the data in standard format is represented by an n × k matrix, we look at the row equivalent version of the above formula, namely, for any data sample X with k dependent variables with covariance matrix S, the Mahalanobis distance squared, D2, of any 1 × k row vector Y is given by
![]()
Using Real Statistics capabilities
To check for outliers we calculate D2 for all the row vectors in the sample. This can be done using the Real Statistics MANOVA data analysis tool, this time choosing the Outliers options (see Figure 1 of Real Statistics Manova Support). The output is displayed in Figure 7.

Figure 7 – Using Mahalanobis D2 to identify outliers
Here the covariance matrix for the sample data (range I4:K6) is calculated by the array formula
=MMULT(TRANSPOSE(B4:D35-I14:K14), B4:D35-I14:K14)/(COUNT(B4:B35)-1)
We could instead use the Real Statistics formula =COV(B4:D35). The inverse of the covariance matrix (range I9:K11) is then calculated by the array formula MINVERSE(I4:K6).
Mahalanobis distance squared
The values of D2 can now be calculated as described above. E.g. D2 for the first sample element (cell F4) is calculated by the formula
=MMULT(B4:D4-$I$14:$K$14,MMULT($I$9:$K$11, TRANSPOSE(B4:D4-$I$14:$K$14)))
The values of D2 play the same role as the z-scores in identifying multivariate outliers. Since the original data is presumed to be multivariate normal, by Property 3 of Multivariate Normal Distribution Basic Concepts, the distribution of the values of D2 is chi-square with k (= the number of dependent variables) degrees of freedom. Usually, any data element whose p-value is < .001 is considered to be a potential outlier. As in the univariate case, this cutoff is somewhat arbitrary.
Example multivariate outliers
For Example 1 of Manova Basic Concepts, the p-values are displayed in column G of Figure 7. E.g. the p-value of the first sample element is calculated by the formula
=CHISQ.DIST.RT(F4,COUNTA($B$3:$D$3))
Any element that is a potential outlier is indicated by an asterisk in column H. We note that none of the p-values in column G is less than .001 and so there are no potential multivariate outliers.
If the yield value for the first sample element (cell B4) is changed from 76.7 to 176.7, then the D2 value in cell G4 would change to 96.76 and the p-value would now become 7.71E-21, which is far below .001. While the value 176.7 might be correct, it would be so much higher than the other yields obtained that we would probably suspect that it was a typing mistake and check to see that the correct value is 76.7.
Worksheet Functions
Real Statistics Functions: The following function is supplied by the Real Statistics Resource Pack:
MDistSq(R1,R2): the Mahalanobis distance squared between the 1 × k row vector R2 and the mean vector of the sample contained in n × k range R1
MOUTLIERS(R1, alpha): when alpha = 0 or is omitted, returns an n × 2 array whose first column contains the Mahalanobis distance squared of each vector in R1 (i.e. the rows of the n × k array R1) and the center of the hyper-ellipse defined by the data elements in R1 and whose second column contains the corresponding p-values based on the chi-square test as described above. When alpha > 0 then only those values for which p-value < alpha are returned.
For example, the Mahalanobis distance squared between the row vector R2 = (50, 25, 5) and the mean of the sample R1 = A4:D35 is MDistSq(R1, R2) = 1.072043.
Referring to Figure 7, the output from the array formula =MOUTLIERS(B4:D35) is identical to the data shown in range F4:G35.
Homogeneity of covariance matrices
As for Hotelling’s T-square test, MANOVA is not so sensitive to violations of this assumption provided the covariance matrices are not too different and the sample sizes are equal.
If the sample sizes are unequal (generally if the largest sample is more than 50% bigger than the smallest), Box’s Test can be used to test for homogeneity of covariance matrices (see Box’s Test). This is an extension of Bartlett’s Test as described in Homogeneity of Variances. As mentioned there, caution should be exercised and many would recommend not using this test since Box’s Test is very sensitive to violations of multivariate normality.
If the larger samples also have the larger variance, then the MANOVA test tends to be robust for type I errors (with a loss in power). If the smaller sized samples have larger variance then you should have more confidence when retaining the null hypothesis than rejecting the null hypothesis. Also, you should use a more stringent test (Pillai’s instead of Wilk’s).
Since the sample sizes for Example 1 of Manova Basic Concepts are equal, we probably don’t need to use the Box Test, but we could perform the test using the Real Statistics MANOVA data analysis tool, this time choosing the Box Test option (see Figure 1 of Real Statistics Manova Support). The output is shown in Figure 8.
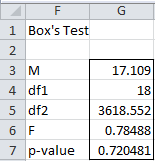
Figure 8 – Box’s Test
Since the p-value for the Box Test is .715, which is far higher than the commonly used value of α = .001, we conclude there is no evidence that the covariance matrices are significantly unequal.
Collinearity
MANOVA extends ANOVA when multiple dependent variables need to be analyzed. It is especially useful when these dependent variables are correlated, but it is also important that the correlations not be too high (i.e. greater than .9) since, as in the univariate case, collinearity results in instability of the model.
The correlation matrix for the data in Example 1 of Manova Basic Concepts is given in range R29:T31 of Figure 2 of Real Statistics Manova Support. We see that none of the off-diagonal values are greater than .9 (or less than -.9) and so we don’t have any problems with collinearity.
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
References
Johnson, R. A., Wichern, D. W. (2007) Applied multivariate statistical analysis. 6th Ed. Pearson
https://mathematics.foi.hr/Applied%20Multivariate%20Statistical%20Analysis%20by%20Johnson%20and%20Wichern.pdf
Rencher, A.C., Christensen, W. F. (2012) Methods of multivariate analysis (3nd Ed). Wiley
I am doing experimental design with two DVs. The Iv is the treatment. I used independent t-test, ANCOVA and paired sample t-test to analyse my data to see the effect of the treatment on the the DVs. Both Dvs are Collaborative Problem Solving Strategies and Learning Motivation. Both DVs are not related. Is the statistical use sufficient? Some argue that I should use MANOVA. I also done normality test and homogeneity test.
I want a justification or explanation that using the independent t-test, ANCOVA and paired sample t-test in my study is sufficient.
Thank you.
Hello Lee,
I don’t have enough information to determine whether the independent t-test, ANCOVA and paired sample t-test are sufficient. One thing to take into account is that since you are performing multiple tests you may need to take experiment-wise error into account (perhaps the Bonferroni correction).
With multiple DVs, MANOVA is commonly used, but if there is no correlation between the DVs then MANOVA doesn’t really add anything.
Charles
Dear Charles,
I am running an unbalanced MANOVA with 11 dependent variables and three groups.
The number of samples in each group are 29, 30 and 39 subjects respectively.
I got p-values 0.0501 (Pillai), 0.0505 (Wilk’s), 0.0511 (Hotelling), and one out the 12 dependent variables resulted statistically significant in the following ANOVA single factor test (p = 7.5 e-5).
Data are normally distributed, but Box’s test was significant with p=0.039.
However, one outlier was detected: after removing it, MANOVA p-values increased to 0.088 (Pillai), 0.091 (Wilk’s) and 0.093 (Hotelling).
I still have the same dependent variable being significant (p=1.81e-4) in the ANOVA single factor test. This time, Box’s test is not significant (p=0.20).
My question is: can I trust on these latter results (that is, with the outlier removed), even if the experiment setup is still unbalanced? How can I interpret that one of dependent variables is statistically significant while the whole MANOVA is not?
Second question: for one of the variables, there are some missing values (4 missing values on total sample = 98). Are they “dangerous” for the reliability of the test?
Thank you very much for your help
Best Regards
Piero
Dear Piero,
Q1 (a). One of the assumptions for MANOVA is that there are no outliers. Thus, I would trust your results without the outlier more than the results with the outlier. However, this doesn’t mean that these results are true for the situation with the outlier. The key question is why is there an outlier? Is this due to some flaw in the data collection or in the research methodology or some other reason? These are usually not easy questions to answer.
Q1 (b). How did you determine that one of the dependent variables is significant while the others are not? If you conducted 11 separate ANOVAs, then you need to take family-wise error into account. Using a Bonferroni correction you need to use alpha/11 as the significance level for each test, at least if you are assuming that all the dependent variables are independent. Since you are using MANOVA, presumably the dependent variables are not independent of each other, but in any case the alpha value needs to be reduced (although perhaps by less than by dividing by 11). In any case, alpha/11 = .05/11 = .004545, which is still larger than p-value = .000181. This implies that it is likely that there is a significant difference between the 3 groups for this one dependent variable. Of course, this assumes that all the assumptions for the ANOVA are met. In particular, you should make sure that the homogeneity of variance is met (Levene’s test). This is the assumption that is most vulnerable to unequal sample sizes.
Q2. You need to decide how to handle the missing data values. If you employ listwise deletion, then your sample size will be reduced from 98 down to possibly 94. You need to take this into account. Alternatively, you can use some other approach for handling the missing data (EM, multiple imputation, etc.)
Charles
Good morning Charles,
thank you very much for your comprehensive answer!
Q1(b): to determine which dependent variables are significant, I just checked the “MANOVA” check box in the Real Statistics Tool, corresponding to perform single ANOVAs with Bonferroni correction. As you said, since the dependent variables are correlated, Bonferroni correction is too conservative. So getting that the significance test verified for that variable (p=0.000181) even with Bonferroni correction, should make me trust this result, isn’t it?
I also applied contrasts after MANOVA and the result is that group c is significantly different from groups (a+b) (Wilk p=0.047); confidence intervals revealed that such difference was due to the same variable that was significant in single ANOVAs.
After your observation, I did Levene’s test and homogeneity of variance is satisfied.
Q2: I applied the EM algorithm implemented in Real Statistics Tool to handle missing data, the results do not change.
So thank you again for your valuable comments and Excel tool!
Best Regards
Piero
Glad I could help, Piero.
Charles
Hey there,
I’m running a MANOVA, but some of the variables are significant in the Levene’s Test. What should I do?
Ines,
See https://www.researchgate.net/post/How-do-I-continue-with-my-analysis-if-the-Boxs-M-and-Levenes-tests-are-significant-in-MANOVA#:~:text=Box's%20M%3A%20If%20group%20sizes,an%20alpha%20level%20stricter%20than%20.
Charles
I want to conduct a study on leadership styles preferences and management factors as predictors of performance among athletes, please which statistical tool is appropriate, ANOVA or manova
Thank you.
Paul,
I would need more information to be able to nswer your question.
Charles
Dear Charles,
First of all, thank you again for your great effort!
About collinearity in MANOVA, you wrote that: “MANOVA […] is especially useful when these dependent variables are correlated, but it is also important that the correlations not be too high (i.e. greater than .9) since, as in univariate case, collinearity results in instability of the model.”
Moreover I read somewhere (but I don’t remember where) that collinearity also affects MANOVA’s power…
Well, if my DVs show a high degree of correlation, do you think it could be a good idea preprocessing them through a PCA in order to remove correlation and then perform a MANOVA over the transformed variables (scores)?
Thank you in advance!
Federico
Federico,
I can’t say for sure, but this does seem like a reasonable approach.
Charles
Please, what is the non-parametric equivalent to one-_way manova???
Henry,
You can use a bootstrap version of MANOVA. The Real Statistic website shows how to do this for one factor ANOVA.
BTW, which MANOVA assumption fails?
See also the following that I found via google:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5798640/
https://www.ecoevol.ufg.br/adrimelo/div/Anderson-2001-AustEcol_non-parametric_manova.pdf
Charles
heyyy
i am currently carrying out a study for my dissertation.
i am doing an online questionaire, my iv is childhood attachments which has three levels and the difference of their effect on the three dvs. so i am using a MANOVA test. does this make sense? i worked out the number of ppts i need using the g power it said 35 but that doesnt sound right? whats the average number of participants you think i should use.
Hi Charles,
I have question regarding MANOVA assumption about the multivariate normal distribution of each population (see Johnson & Wichern pp. 297). Do we need to perform multivariate normal for each population? Please give me the explanation about how the test should be performed.
Kurnia,
I don-t have access to Johnson & Wichern pp. 297 and so I can-t read what was said there. In any case, multivariate normality is a requirement for MANOVA. Since this is difficult to check, usually people check to see whether the data for each dependent variable is at least normally distributed (univariate normality). The Real Statistics software does provide Mardia’s test for multivariate normality. See https://real-statistics.com/multivariate-statistics/multivariate-normal-distribution/multivariate-normality-testing/
Also the MANOVA data analysis tool has an option for identifying multivariate outliers. This can be useful since the outliers tend to be what undermined the multivariate normality assumption.
Charles
thanks for a comprehensive discussion. I just wanna ask what would be the possible size if I have 6 independent variables with 2 levels, 2 levels, 5 levels, 3 levels, 3 levels and 2 levels respectively with 3 dependent variables. Please help me in deciding the sample size. Best regards.. Thank you so much..or it is possible to have it?
Miles,
Real Statistics doesn’t yet support sample size calculations for MANOVA. You can use the G*Power tool for this. See
http://www.gpower.hhu.de/en.html
Charles
Hi Charles,
See equation 4 in the attached document “Financial Applications of the Mahalanobis Distance.” It suggests a way to introduce weights to Mahalanobis distance measure. It would be great if you can incorporate that logic into your figure 7 (for yield, water and herbicide) and your discussion of how to reproduce the cells in range I4 to I6 (using MMULT) and cell I4 using MMULT.
Charles,
Please see the attached link
redfame.com/journal/index.php/aef/article/download/511/497
Thanks Steve, I will take a look at the article.
Charles
Any thoughts on how to do this?
Steve,
If you are referring to your recent comments, I have had time to look into this yet since I have been busy putting together the next release of the Real Statistics software.
Charles
Charles,
I find your website to be an extremely valuable resource. Would it be possible to modify figure 7 in the MANOVA Assumptions discussion to incorporate a vector of weights to correspond to the relative importance of yield, water and herbicide. For example, yield=.65, water=.30 and herbicide=.05. In addition, it would be helpful for you to revise the excel syntax for the covariance matrix (starting in cell I4) and and D squared in cell F4. There are many applications in finance where unequal weights are desirable, e.g,, total returns to the various sleeves of an investment portfolio.
Steve,
I will need to look into this.
Charles
Thanks very much.
Dr Dr Charles Zaiontz;
I wish to thank you for sharing so generously your expertise and work on statistics using EXCEL, which is easily accesible to most people.
Given my limited knowledge in statistics, I fell on your website while doing a general search on a way to cover my statistical analysis on a survey project of mine involving health care providers and a means of improving their empathic communication skills using a simple protocol (similar to other such protocols, validated especially in the field of ooncology).
I therefore take the liberty of exposing my problem, in hope of obtaining some advice on the issue (ideas have been provided by others elsewhere, but no one seems to be sure).
The question boils down to
Is there non parametric equivalent to repeated measures MANOVA,
in the case where is the assumption being violated is that of the MEASUREMENT:
ORDINAL variables instead of higher measure levels, ie INTERVAL variables,
as required by MANOVA.
I’m trying out “Optimal Data Analysis” which circumvents all these difficulties, but I still need a “classical statistics” type of analysis.
The main study analysis involves
no Independent Variabe (intra-sample analysis only),
multi DVs
[8DVs with 5 levels:
2 Levels, each for a pre post [i.e. repeat] measure;
and 1 level, post only;
with all measures being “noncommensurate” between DV levels,
although all on a 5-point Likert scale, therefore ORDINAL],
to answer the question
of pre vs. post differences
following an intervention (longitudinal, time-dependent study),
with regard to each DV and level.
Thank you once again for your generosity and time.
Most appreciative,
Georgios
Georgios,
You can perform MANOVA, ANOVA and many other tests with Likert scale data provided the distances between the scales are equal, i.e. it is assumed that the amount of difference between 4 and 3 is the same as between 2 and 1, etc. This works better for a 7-point Likert scale than a 5-point Likert scale, but many would still use a 5-point Likert scale.
I have also come across the following article describing a nonparametric version of MANOVA:
http://www.entsoc.org/PDF/MUVE/6_NewMethod_MANOVA1_2.pdf
Charles
Greetings, Charles!
Thank you very much for your prompt and informative response!
In one of the links you provided in the present discussion
(http://psycnet.apa.org/journals/med/1/1/27/)
Dr Finch states: “In order for MANOVA to work appropriately, there are assumptions which must be met, and which are very similar to those required for the use of ANOVA:
(1) observations must be independent,
(2) the response variables are multivariate normal,
and (3) the population covariance matrices are equal across the levels (P) of the independent variable.”
NORMALITY and equal covariance are necessary prerequisites and, indeed, there is no mention of having to deal with higher level measures (INTERVAL or a RATIO measure) as opposed to simply ORDINAL measures, which is re affirmed by your kind response.
====
In a discussion on ANOVA (in another forum) the following RECENT article is cited, as concerns violation of the “equidistance” principle
1. Lantz B. The impact of non-equidistance on Anova and alternative methods. Electron J Bus Res Methods [Internet]. 2014;12(1):16–26. Available from: http://www.scopus.com/inward/record.url?eid=2-s2.0-84912137275&partnerID=40&md5=e284285938f919aba5e5acbf52a90cfc
where the “take-home message is that ANOVA seems relatively insensitive to violations of the assumption of equidistance given that the other assumptions of normality hold; otherwise, one should look to robust alternatives”.
QUESTION 1:
Could this “relative insensitivity” of ANOVA to violations of the assumption of equidistance
be eventually extended to MANOVA?
====
The article you suggested
http://www.entsoc.org/PDF/MUVE/6_NewMethod_MANOVA1_2.pdf
is really very “high tech” for me.
It does not seem to deal with REPEAT measures
Furthermore, in the ASSUMPTIONS section, one reads
ASSUMPTIONS: “The only assumption of the test is that the observations (rows of the original data matrix) are exchangeable under a true null hypothesis. To assume exchangeability under the null hypothesis is generally to assume that the observations are independent and that they have similar distributions (e.g. Boik 1987; Hayes 1996). By ‘similar distributions’, I mean similar multivariate dispersions of points, not that the points are necessarily multivariate normal”.
I assume that REPEAT MEASURES (pre vs post, ie only TWO occasions) are perhaps NOT independent…
Yet another paper cited by another researcher, and dealing with repeat measures, is the following
Robert B. McCall · Mark I. Appelbaum “Bias in the Analysis of Repeated-Measures Designs: Some Alternative Approach” – Child Development 44(3) · September 1973
DOI: 10.2307/1127993
Abstract: “The conventional analysis of variance applied to designs in which each subject is measured repeatedly requires stringent assumptions regarding the variance-covariance (i. e., correlations among repeated measures) structure of the data. Violation of these assumptions results in too many rejections of the null hypothesis for the stated significance level. This paper considers several alternatives when heterogeneity of covariance exists, including nonparametric tests, randomization and matching procedures, Box and Greenhouse-Geisser corrections, and multivariate analysis. The presentation is from an applied rather than theoretical standpoint. Multivariate techniques that make no covariance assumptions and provide exact probability statements represent the most versatile solution.”
Question 2
Given all this information
– that non equidistance is not as iviolable as considered in the past, at least as far as ANOVA is concerned,
– that my scales were meant to be equidistant, although limited in choice (I was told that I’d need many more respondants had I opted for a 7-point instead of 5-point Likert scale)
– that data may most likely be SKEWED in repeat measure analysis (positive effect of some intemediate intervention)
– that I don’t know much about statistics
can I just still attempt a MANOVA with my data?
As an example, here is a data outlay
If item 01 is “eye contact” and item 02 is “please tell more about your problem”, with another 6 items of similar nature
can I say that my educational intervention to guide health care workers into having a more empathic raport is useful –
that is, can I use MANOVA to show that ALL POST is quite different from PRE?
QuaNTity stands for how many times a person used “Item 01” etc PRE as opposed to POST educational protocol (intervention)
QuaLIty stands for how CONSIOUSLY did a person use “Item 01” etc PRE as opposed to POST eeducational protocol (intervention)
IMPACT stands for “in general, in your lifetime experience, do you feel that “Item 01” etc is “important” in developing raport?
ALL scores are on a 5 point Likert scale, but the scale does not measure the same type of “units” or “ideas”…. (construct?)
*******************************************Respondant 01*******Respondant 02****respondant n
**************************Likert score******0 to 4 **************0 to 4**************0 to 4
Item 01
********QuaNTity********P_01QT_PRE*************1*******************0*******************2***
************************P_01QT_PST*************3*******************2*******************3***
********QuaLity*********P_01QL_PRE*************2*******************0*******************1***
************************P_01QL_PST*************4*******************3*******************2***
********Impact**********P_01_Impct*************2*******************3*******************4***
**********************************************
Item 02
QuaNTity P_02QT_PRE 2 1 3
P_02QT_PST 3 2 4
QuaLity P_02QL_PRE 1 1 0
P_02QL_PST 3 4 2
Impact P_02_Impct 3 4 4
*****************************************
etc….
Once again, I really appreciate your very educational blog, and your kind responses to everyone, including me.
Sincerely,
Georgios
Georgios,
Thanks for sharing this information with me and the others in the community.
Question 1: I am not really sure whether the observation about Anova extends to Manova I haven’t read the Anova article. I wouldn’t be surprised if it did, but I am not certain.
Question 2: As for Question 1, I can’t say for sure whether you can relax all the assumptions in the way that you have described. I am surprised that you are being advised to have a larger sample size for 7-point Likert than 5-point Likert. I rather doubt that that is true. Regarding repeated measures, generally the test is on the difference between the data points, and so if the two samples are similarly skewed, then you should be ok. All in all, I would use Manova, but document that there is some risks regarding the assumptions.
Charles
Thank you very much, Charles!
Hi Charles,
I apologize 4/14/121 refers to 4 responses from individuals in level/position 1, 14 responses from individuals in level/position 2, and 121 responses from individuals in level/position 3. I am using a group differences design with one categorical IV and two interval DV’s. Do you think these combinations too small or too uneven to attempt using MANOVA?
Mia,
With such an unbalanced model, you have the following shortcomings:
1. It is very unlikely that the equal covariance matrices assumption will be met
2. Power will be very low.
Charles
Hi Charles,
I am using a group differences design with one categorical IV and two interval DV’s. The data is 4,14,121 for the 3 levels/positions. Do you think these combinations too small to attempt using MANOVA?
Mia,
Sorry, but I don’t know what 4,14,121 means.
Charles
Charles,
I noticed the question above about DVs and correlation. Should you use MANOVA if your 2 DVs are suggested to be correlated?
Thanks!
Mia,
This is the key reason for using MANOVA instead of separate ANOVA’s.
Charles
please wht are the consequences of the failure of the assumptions of MANOVA?
It depends on which assumption. E.g. MANOVA is pretty robust to violations of normality. Depending by how much the assumptions are violated, the results can be completely worthless.
Charles
Dear Charles,
Thanks for valuable guidance.
I have one question: how I can check distribution of residuals in Manova in SPSS?
What if their distributions are not-normal? Whether MANOVA still works?
Thanks in advance.
Sorry Ella but I don’t use SPSS.
Charles
Thnaks for replay.
Please, take some time to see my problem:
I have one IV with two levels 18 interval DVs. Numeber of participants is 50 per group (level of IV). The most DVs are not normally distributed according to K-S test, but plots and Sk, and Ku values do not look so bad even thought there are outliers . When it comes to mulivariate normallity and Mahalanobis distance, three outliers are detected. Also, Box’s Test of Equality of Covariance and Bartlett’s Test of Sphericity are both (highly) significant- p<.001.
So, I was wondering, does Manova still works in my case according to all mentionded violations. Is it still pretty robust?
I have read that for Manova as well as for linear regression assumtion is that residuals are normally distributed.
So does Manova still works if residals are not normally distributed?
Thanks in advance.
Ella,
I don’t use SPSS and so I don’t know what tests for multivariate normality in SPSS. The approach used in Excel is described on the referenced webpage.
As described on the referenced webpage, MANOVA is quite robust to violations of normality and should give good results unless the data is highly skewed.
Charles
Charles,
I have one independent categorical variable with two levels, one independent categorical variable with three levels, and two dependent interval variables. Each research question includes one IV with the two DV’s. I intend to use one-way MANOVA with a convenience sample of about 100 likely with small numbers in each group. Does using a convenience sample automatically exclude MANOVA as an option?
Thanks!
Technically most statistical tests assume a completely random sample, but it is very common to use a convenience sample anyway. I would still use MANOVA (provided it is the right tests and the other assumptions are met) and mention the type of sample that you are using when reporting your results.
I would be concerned that your sample is sufficiently large to have enough statistical power. You can use the G*Power software to test the power of your test.
Charles
Hi Charles,
For one RQ, I have a categorical IV (status) with two levels (employees-9 or volunteers-139) and two interval DV’s. Would MANOVA be possible with so many more in one group than the other? For RQ2, I have a different categorical IV (position) with three levels (1,2,3) and 2 at level 1, 2 at level 2, and 5 at level 3 for a total of 9 respondents using the same two interval DV’s. The last RQ is the same as RQ2, with 4,14,121 at the 3 levels/positions. Are any of these combinations too small to attempt using MANOVA?
Hi Mia,
Although I haven’t completely understood the design that you described, here are some comments:
1. With a severely unbalanced design you need to be very careful about the assumption that the within groups covariance matrices are equal. You should test this assumption using Box’s M test. If this test is significant at less than .001, the test is likely not to be very accurate. You should only use Pillai’s trace criterion in this case.
2. With only 9 sets of data I wouldn’t expect too much from the analysis.
Charles
Hi Charles,
Thanks for the speedy reply! It is a group differences design. I agree about the 9 sets of data. The last RQ does not involve the 9 sets, but instead 4,14,121 at the 3 levels/positions. The sets for the last RQ should work better, correct?
Dear Charles,
Thanks for all your guidance.
I have a question about sample size in manova. I have a dependent variable with five levels. I wonder whether I can run manova with 20 participants. Does it give reliable results?
I would appreciate your help.
Thanks for a really useful article, Charles.
I have a seven-category independent variable where sample sizes in each category are relatively small (range 6-47, 3 are <10) and two dependent variables that are significantly correlated with each other (r=.591, p<.001).
When performing my MANOVA in SPSS, my Box's Test of Equality of Covariance and Bartlett's Test of Sphericity are both (highly) significant – this seems to be mainly due to a) the variance in the second smallest sample category being a lot smaller than that for the largest category for both dependent variables b) the smallest sample category having a particularly large variance on one of the dependent variables .
You say that "if the larger samples also have larger variance then the MANOVA test tends to be robust for type I errors (with a loss in power). If the smaller sized samples have larger variance then you should have more confidence when retaining the null hypothesis than rejecting the null hypothesis. Also you should use a more stringent test (Pillai’s instead of Wilk’s)."
Does this mean I lose both power and confidence when looking at any significant test results (Pillai's, Wilks', Hotelling's or Roy's Largest Root)? Should I decrease my alpha accordingly (eg. make it .001 instead of .05)? Any thoughts welcome…
In this case, there is more chance that if you find a significant result, this is incorrect.
Note that if you reduce alpha to say .01 instead of .05, this will reduce power.
Charles
I have a question about a repeated measures manova (RMA).
I have 3 variables which i would like to compare with each other.
However, the 3 variabeles are not on the same scale (they have different ranges: 0-30, 0-80, and 0-19(raw score)). I transformed the variables into z-scores.
Is it still possible to do a RMA with variables consisting of zscores?
cause when using zscores all variables will have a mean of zero, right?
The mean of z scores will be zero. It is possible to do RMA using zscores, but I am not sure why you would want to perform repeated measures manova when the three variables have different scales.
Charles
Thanks for this useful explanation of MANOVA.
Presumably when the assumptions for MANOVA are not met, then a non-parametric test must be used. I was wondering what is the non-parametric equivalent of MANOVA?
Here are two articles which you may find useful:
http://www.entsoc.org/PDF/MUVE/6_NewMethod_MANOVA1_2.pdf
http://psycnet.apa.org/journals/med/1/1/27/
A key question is which assumption(s) are not met. MANOVA is pretty forgiving to violations of normality.
Charles
Dear Charles,
If my data is non-parametric (i.e. ShapiroWilk score is p<0.05) can I still use to MANOVA to find out if factors affecting my outcome variable are independent factors?
Thanks!
Jessica,
If you are asking me whether MANOVA still works even with data that is not multivariate normal, the answer is that the test is usually pretty robust to violations of the multivariate normality assumption.
Charles
Thank you for this very useful course. I have 2 questions:
1) Can I use MANOVA if my 2 dependent variables are not signficantly correlated?
2) If yes, can I use 2 observed variables measured differntly to form one dependent latent variables. Eg: Behavior problems scale (The higher the score is, the worst the person is) and self-esteem (The higher the score is, the better the person is)?
3) What are the requirements for such combination? Can I call such combination for ex. psychological adjustment?
Thank you for your response
1) You can use MANOVA when there is little correlation between the dependent variables, but in this case, you might be as well off using two separate ANOVA tests (although you might get some benefit from reducing experiment-wise error)
2) Sorry, but I don’t understand your question.
Charles