Univariate case
In the univariate case, we have two independent random variables and want to determine whether the population means of the two random variables are equal, i.e. H0: μx = μy. To test this hypothesis we create a random sample for each variable. Assuming that the sample for x has size, mean, and standard deviation respectively nx, x-bar, and sx, and that the sample for y has size, mean, and standard deviation respectively ny, y-bar, and sy, we define the following statistic
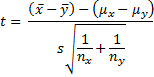
where s is the pooled standard deviation defined by
![]()
It then follows that the t-statistic defined above has a t distribution with nx + ny – 2 degrees of freedom, i.e.
![]()
provided the following assumptions are met
- The populations of x and y have unique means and there are no distinct sub-populations with different means
- The populations of x and y have a normal distribution
- The variances of the two populations are equal (homogeneity of variances)
- The samples for x and y are random with each element in the sample taken independently
Regarding the normality assumption, if nx and ny are sufficiently large, the Central Limit Theorem holds, and we can proceed as if the populations were normal. It turns out that the t-test is pretty robust for violations of the normality assumption provided each population is relatively symmetric about its mean.
The null hypothesis is rejected if |t| > tcrit. Also note that by Property 1 of F Distribution, an equivalent test can be made using the test statistic t2 and noting that
![]()
Also, t2 can be expressed as follows:
![]()
where z-bar = x-bar – y-bar and µz = µx – µy.
Multivariate case
We now look at a multivariate version of the problem, namely to test whether the population means of the k — 1 random vectors and Y are equal, i.e. the null hypothesis H0: μX = μY.
Definitions and Properties
Definition 1: The Two-sample Hotelling’s T-square test statistic is
![]()
where S is the pooled sample covariance matrix of X and Y, namely
![]()
where SX is the covariance matrix of the sample for X, X-bar is the mean of the sample, and the sample for each random variable xi in X has nx elements, and similarly, SY is the covariance matrix of the sample for Y, Y-bar is the mean of the sample, and the sample for each random variable yi in Y has ny elements.
Note the similarity between the expression for T2 and the expression for t2 given above.
Property 1: For nx and ny sufficiently large, T2 ~ χ2(k)
For small nx and ny, T2 is not sufficiently accurate and a better estimate is achieved using the following theorem.
Property 2: Under the null hypothesis
![]()
where n = nx + ny – 1.
If F > Fcrit then we reject the null hypothesis.
Example 1
A certain type of tropical disease is characterized by fever, low blood pressure, and body aches. A pharmaceutical company was working on a new drug to treat this type of disease and wanted to determine whether the drug was effective. They took a random sample of 20 people with this type of disease and 18 with a placebo. Based on the data in Figure 1 they wanted to determine whether the drug is effective at reducing these three symptoms.

Figure 1 – Data for Example 1
The difference in mean vectors, the sample sizes, and the covariance matrices for the drug and placebo samples are displayed in Figure 2, as well as the pooled covariance matrix. Here we are assuming that the covariance matrices are approximately equal and so a better estimate of each of these covariance matrices is given by the pooled covariance matrix (see Assumptions below).

Figure 2 – Mean vectors, sample sizes, and covariance matrices
We now calculate T2 using the array formula
=MMULT(TRANSPOSE(L4:L6),MMULT(MINVERSE((1/J7+1/K7)*Q11:S13),L4:L6))
Using Property 2, we perform Hotelling’s T2 test for independent samples, as described in Figure 3.

Figure 3 – Hotelling’s T2 test on two independent samples
Since p-value > α (or F < Fcrit), we can’t reject the null hypothesis, and conclude there is no significant difference between the mean vectors for the drug and placebo, providing evidence that the drug is not effective in reducing symptoms.
Example 2
The pharmaceutical company from Example 1 also had another drug that they wanted to test for effectiveness in reducing the topical disease’s symptoms. Once again another random sample of 20 people with the disease was given the drug. Based on this data and the data for the control group, determine whether there is a significant difference between the drug and placebo in reducing the symptoms.

Figure 4 – Data for Example 2
Repeating the analysis of Example 1, we obtain the results shown in Figure 5.

Figure 5 Analysis for Example 2
This time, we see there is a significant difference between the drug and the placebo in treating the symptoms. We summarize the results as (T2 = 44.84.45, F = 14.12, df = 3, 34; p < 0.0001).
Click on the following link for additional information about Hotelling’s T2 test for two independent samples, including confidence intervals, effect size, and assumptions:
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
References
Penn State University (2013) Hotelling’s T-square. STAT 505: Applied multivariate statistical analysis (course notes)
https://online.stat.psu.edu/stat505/lesson/7/7.1/7.1.3
Rencher, A.C. (2002) Methods of multivariate analysis (2nd Ed). Wiley-Interscience, New York.
http://math.bme.hu/~csicsman/oktatas/statprog/gyak/SAS/eng/Statistics%20eBook%20-%20Methods%20of%20Multivariate%20Analysis%20-%202nd%20Ed%20Wiley%202002%20-%20(By%20Laxxuss).pdf
Johnson, R. A. and Wichern, D. W. (2007) Applied multivariate statistical analysis. 6th Ed. Pearson.
https://mathematics.foi.hr/Applied%20Multivariate%20Statistical%20Analysis%20by%20Johnson%20and%20Wichern.pdf
Is there a way we can download this data?
Go to Examples Workbooks
Charles
Hi,
I’m going through the examples and I think there’s a mistake in df2, which should be 33 (n-k-1), and not 34. Thank you also this is a great article and helped me a lot.
Frédéric,
df2 = n-k where n = n1+n2-1. Thus df2 = n1+n2-1-k = 20+18-1-3 = 34.
Charles
Hi, I really appreciate this site and your add on for Excel!
I have a situation where I am testing the effect of a classroom intervention on test performance, comparing a year in which the intervention was used with the previous year in which it was not used. The problem is that the test is divided into four parts and students must pass one part in order to move on to the next. So the sample size is not only different for the two independent samples, but is different for each “round” of the test. But I would like to compare the effect on each exam component between the two years. Thus far, I have treated each comparison as sort of an individual experiment and have run separate t-tests. I have justified this not only with the situation explained above, but also because there is no change in the composite score between the two years and a significant change for only one part according to the separate t-tests. Also, this is sort of an secondary, exploratory aspect of the research and not relevant for the central research question.
So my first question is: should I be very concerned about a Type I error when doing separate t-tests in this case?
The second question is: if I use the t-squared function available in the package, does it matter if the sample size is reduced each round? If not, will the function simply ignore missing values? If it does matter, which test would you recommend instead of t-squared?
Thanks!
Mike,
If the same students are taking the test two years in a row, then you can’t use an independent sample test. Instead you would use a paired sample test. You also have the problem that the students might learn about the test in the first year and so do better in the second year (assuming the test is the same or similar both years).
I don’t see any problem doing 4 separate paired t tests, one for each of the 4 parts. There is no problem using different sample sizes for each part, but you do need to have the same students represented for both years in order to use a paired t test. This is a problem for parts 2, 3 and 4. E.g. if student A fails part 1 in year 1 but passes in year 2, then there won’t be a score for part 2 for year 1 but there will be a score for year 2. If there aren’t too many of these cases, then you can simply eliminate such cases when performing the paired t test. Alternatively you can assign a score of zero for part 2 when a student doesn’t pass part 1, although this reasonable only if such a score makes sense (which it probably doesn’t).
1. Since you are performing multiple t tests, you should take familywise error into account. This is explained at
https://real-statistics.com/hypothesis-testing/familywise-error/.
2. Since the sample size is reduced each round, I don’t see how you can use the T-square test.
Charles
Thank you very much for the fast and helpful response!
Actually, I compared two different cohorts of students, so two independent samples and 4 separate two-sample t tests. My sense was this was ok because the only outcome on which the intervention was having an effect was quite clear from the test statistics and from the raw data. Good to know that there is another way to reduce the probability of making a Type-1 error than performing more complicated tests.
Two follow-up questions:
1) It is too late for me to do this with the current data, but for future reference could I have performed one of the multiple imputation techniques offered in your package in order to fill in the missing data which would be necessary for a t-square test? I opted against such a complex data analysis given the data and the pseudo experimental design, but especially for the sake of simplicity in both analysis and presentation of results.
2) The intervention I mention in the first post was a series of classroom learning activities which were scored. I also performed multiple (i.e., four separate) linear regression analyses to understand the relationship between students’ scores on each component of the test (at the end of the course) and their average scores on the learning activities. As completion of the learning activities (and therefore average scores) were dependent on course attendance, I also ran four separate regression analyses with attendance as an independent variable. I felt as if it would have been better to perform a multivariate multiple linear analysis in this case, but that even this would have been inappropriate because one of the independent variables is dependent on the other. Rather than researching some Bayesian technique (as a non-statistician), I opted for simplicity again. My question is if you also see no problem with this choice, or if you would have suggested another test…
PS I have recommended your site and package to several colleagues!
Mike,
1. Probably not since the data is not missing at random. If data is missing on part 2 it will also be missing on parts 3 and 4.
2. You could try to analyze your data by using bootstrapping.
Charles
1. Exactly what I thought! I will just set alpha at 0.1 for the sake of simplicity.
2. Interesting. I know what bootstrapping is, but have never used the technique to analyze my own data. Are you suggesting that I bootstrap the calculation of r for each relationship simply to increase the significance of each coefficient? Or would it also be necessary to then run ANOVA to test the significance of the differences between the bootstrapped coefficients? The confidence intervals would suffice, right? Last question, promise!
Mike,
The Real Statistics website described various ways of performing bootstrapping. See
Resampling
I can’t say exactly how to use bootstrapping for your situation, but when the usual analytic techniques won’t work, often bootstrapping could be used.
Yes, if bootstrapping can be applied, then you would look at the confidence intervals generated.
Charles
hello sir
if i have 3 sample and also given varianc covariance matrix and we have to test the equality of three means ..then what test will be applied..?
Based on my understanding of your situation, MANOVA might be the test to use.
Charles
Sir, MANOVA is used for analysis of variance can we use here Hotelling T square statistic since here we have to test equality of means.
Nayan,
In general, with two independent variables you can use Hotelling’s T square instead of MANOVA.
Charles
How can I find the functions for each matrix? I’m trying to use Excel since I don’t have access to SAS, but I don’t see any instruction on how to accomplish this. Thanks for your help.
See the following webpage
https://real-statistics.com/multivariate-statistics/hotellings-t-square-statistic/hotellings-t-square-real-statistics-functions/
Charles
Dear Charles,
I have a question regarding Similarity Measures for nominal data sets
What I want to measure is how similar in a quantitative or statistical way between them so that my results are consistent. Therefore, I thought Hotelling t2 test is quite proper way to measure how similar they are.
but since it is categorical (Nominal) data set, I am not sure I can use this or not.
Do you think I can still use Hotelling T2 test for comparing two nominal groups data set? or is there other ways like Hotelling t2 test for nominal data sets?
If I can get any comments or advice, I would really appreciate it.
Best Regards,
Jacob,
Are you referring to data sets that don’t contain numeric data? Shortly, I plan to add some information about indices of diversity which may be helpful to you.
Charles
Thanks for your reply Charles!
Yes, discontinuous/qualitative/ nominal datasets and I was curious about the Hotelling T2 test is still possible to assess for those non-numeric datasets.
Can’t wait for your update~!
Sincerely,
Hi George,
Thank you very much for this amazing work and also very much appreciated for making this an open source. I have a question, I used your excel function for “Hotelling T-square Test” and then I used the method Mandeville provided in the following link also copied and pasted below on the same data, however, my F and P values are different any suggestion?
https://stat.ethz.ch/pipermail/r-help/1998-November/003045.html
Cheers,
Nelly
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
hotelling <- function(d1,d2){
k <- ncol(d1)
n1 <- nrow(d1)
n2 <- nrow(d2)
xbar1 <- apply(d1,2,mean)
xbar2 <- apply(d2,2,mean)
dbar <- xbar2-xbar1
v <- ((n1-1)*var(d1)+(n2-1)*var(d2))/(n1+n2-2)
t2 <- n1*n2*dbar%*%solve(v)%*%dbar/(n1+n2)
f <- (n1+n2-k-1)*t2/((n1+n2-2)*k)
cat("F:",f,"\n")
cat("PROBABILITY:",1-pf(f,k,n1+n2-k-1),"\n")
}
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Nelly,
I have tested the various Real Statistics methods against some other sources and found that they match. There are many techniques available and so I cannot guarantee that the result will match with all of them. How much difference do you find in the F and p values between the two approaches?
Charles
Dear Charles
How do we use Hotelling T 2 to test mean vector of many
Samples.
Is there available code and package for doing Hotelling T square in R
Thanks
Adeyemi,
You use MANOVA instead of Hotelling T2 in this case.
There probably is a package in R, but I don’t use R so I can’t comment further.
Charles
Hello,
Thanks for this example. But why are the raw data tables seemingly identical between the first and second case examples (Figure 1 & 4)? This makes the learning example very difficult to comprehend, IMHO.
BR,
Jeff
Hello Jeff,
The data in Figure 4 is not correct. I have now replaced this figure with the correct information.
Thank you very much much for catching this error. I really appreciate your help in making the website better.
Hopefully this makes things clearer.
Charles
Charles,
My email is cristian.gradinaru@circassia.com if you prefer to contact me directly.
regards,
Cristian
Hi Charles,
You may remember I contacted you a couple of months ago regarding analyzing some multivariate data. In the meanwhile I have derived a new test starting from first principles which we were going to publish. We were also looking for another statistician would be willing to a co-author on the paper who would be able to double-check the method and possibly provide additional input. Would you be potentially interested in participating in this?
regards,
Cristian
Cristian,
I could be interested, but first I would have to see the new test that you developed.
Charles
Absolutely, is there an email address where I can send the material to you directly?
regards,
Cristian
Cristian,
See Contact Us for the email address.
Charles
Hello Charles,
Some people take the inverse of the pooled covariance matrix when calculating the T-square while others like i have also seen here multiply the pooled covariance matrix the sum of the inverse of the sample size before taking the inverse of the result obtained.
I would like to know the difference and the reason.
Thanks
Koko,
The difference is a multiplicative factor of 1/(1/n1+1/n2). I don’t know why someonbe would leave out this factor.
Charles
Hello Charles,
Thanks. That helped a lot.
Here’s a quote from a text by Alvin Rencher PP123.
“T 2 = n1n2/n1 + n2 (y1 − y2)Spl-1 (y1 − y2), (5.9)
To carry out the test, we collect the two samples, calculate T 2 by (5.9), and reject H0 if T 2 ≥T 2 α,p,n1+n2−2.
The T 2-statistic (5.9) can be expressed in characteristic form as the standardized distance between y1 and y2:
T 2 = (y1 − y2) ((1/n1+ 1/n2)Spl−1)(y1 − y2), (5.10)”
Solutions from both dont seem to be equal. Pls which is most appropriate, kindly advice.
Thanks
I am not familiar with the form in the text by Alvin Rencher. The form in the website is correct.
Charles
Thanks Charles. I appreciate a lot
Hello Dr Charles,
I appreciate all your contributions to knowledge via this medium
What is the difference between the Hotelling’s T-square statistic that has the sum of two fractions multiplied with the covariance matrix and the statistic without that fractions as published in some books? If there is a significant difference, when should they be used?
Thanks with regards
Koko,
Sorry, but I don’t understand your question. Can you provide some additional detail or context?
Charles
Hi Charles,
I downloaded the macro file RealStats.xlam to use with my own calculations in an Excel spreadsheet and I was wondering if there is a way to embed it in my own spreadsheet so I don’t have to use both files. I am only using the COV function defined in your macro file so I considered creating a local macro that only has that function defined, but I am unable to open RealStats.xlam for viewing (it is password-protected).
regards,
Cristian
Cristian,
I understand from your subsequent comment that you have now figured this out.
Charles
Cristian,
Sorry, but as I am sure you can understand I don’t distribute the source code for the Real Statistics Resource Pack. This is the reason why it is password protected.
If you use RealStat.xlam as an Excel addin (as described on the website) it is quite seamless to use and so shouldn’t be an added burden. In any case, it is quite easy to create your own macro for the COV function. How to do this is more or less described on the website.
Charles
Hi Charles,
thank you for your reply. Do you have any thoughts on my other question (posted March 14th below)? There I am essentially interested in comparing two datasets which can be seen as two 7D-vectors whose elements are 12-value sets. The 12 values that make up a vector element are interchangeable (i.e. not ordinal) and the 7 elements that make a vector are NOT interchangeable (i.e. ordinal; each has an identity as the 1st vector element, 2nd vector element etc.). The idea is to test whether one vector is “larger” overall than the other.
regards,
Cristian
Cristian,
I haven’t forgotten your question, but lately I have been overwhelmed with lots of comments/questions and work in updating the website with information pertaining to the latest release (esp. about time series analysis), and so sometimes my responses will, by necessity, be delayed.
Charles
Ok, thanks a lot for taking the time to keep this website, it is an excellent resource.
regards,
Cristian
Hi Charles,
Thanks for making this information available on your website and for kindly providing the excel templates. I have been doing Hotelling’s T^2-testing on some data of my own, and I noticed that you use matrix operations in excel, i.e. {} formulas, to calculate the covariance matrices. I see that e.g. in the case of example Hotel 3a in your Real-Statistics-Multivariate-Example.xls spreadsheet, you calculate the covariance matrices for the placebo and drug, respectively, using this formula:
{=’C:\Users\Charles\AppData\Roaming\Microsoft\AddIns\RealStats.xlam’!Cov(E6:G23)}
Presumably RealStats.xlam contains the relevant data (patients vs. symptoms). I do not see a predefined Cov function in Excel that would return a covariance matrix (there is covar and covariance.s and covariance.p that return scalars by taking the covariance of two vectors). Is that a function that you have written yourself or that is available as an add-in?
regards,
Cristian
Hi Cristian,
The COV function is not a standard Excel function. It is available in the Real Statistics add-in. You can download the add-in for free from the following webpage
Download Resource Pack.
Charles
Hi Charles,
thank you for pointing me to the right file.
I do have another question about the general applicability of Hotelling’s T2-test. In your example you have a list of patients with a set of properties for each patient (fever, pressure, aches). How would you handle a situation where you have a set of responses that are interchangeable (e.g. 10 measurements of the temperature for patient 1 and 10 measurements of temperature of patient 2; 10 measurements of pressure for pt 1 and 10 for pt 2; and 10 measurements of aches of pt 1 and 10 of pt 2). The goal is to compare whether pt1 shows improvement to treatment vs. pt2 (e.g. pt1 received a drug and pt2 received placebo). If you went on this case to calculate a 3×3 matrix for each patient, the matrix would change if you interchanged say measurement 1 of pt1’s fever with measurement 2 of pt1’s fever, whereas in real life there would be no difference expected. Again, this differs from your example because there you can’t exchange pt1’s fever with pt2’s and expect the same result.
It is essentially the difference between a paired and unpaired t-test in the multivariate case.
Hi Charles, I got this figured, I didn’t realize you already have that on your website. I do have another question though. A simple t-test (or variations such as Welch’s test) compares scalar population means. Hotelling’s test compares vector population means. Is there any test that will compare matrix population means?
For example if I have measurements of blood levels of say 7 analytes which are known to increase in the untreated disease condition and 20 patients, and record the same blood levels for the same 7 analytes and the same 20 pts. upon treatment. The population consists of 12 sets of measurements for each patient and each analyte. Then you would effectively have a 7×20 matrix of means (average analyte level per patient per analyte) in the untreated condition and a 7×20 matrix of means in the drug-treated condition that you want to compare (and hopefully reject H0 that they are equal). regards, Cristian
Cristian,
I don’t completely follow your example. I don’t see how the patients are figuring in your matrices. Do mean 7×12 matrices? In any case, a 7×12 matrix can be mapped into a vector of size 7×12 = 84, and so you could still use Hotelling’s T-square test. There is a good chance that you instead want a multi factor MANOVA though.
Charles
Hi Charles, I’ll try to explain this in more detail. I have 20 patients, and I am taking blood from each of them to measure 7 (different, but likely correlated) analytes’ concentrations. For each patient and each analyte, I measure the analyte concentration 12 times.
That leaves me with a 20 pts x 7 analytes x 12 measurements matrix.
I also repeat this experiment on the same set of patients, this time after they’ve been given a drug which is hypothesized to alter (increase) the analytes’ concentrations. That gives me another 20 x 7 x 12 matrix.
It is clear that for a given patient i and analyte k, this reduces to a 12-measurement sample (placebo) vs. 12-measurement sample (drug), in which case t-testing is suitable.
I want to know:
A. Does analyte k show a statistically significant response to drug treatment? I.e. is analyte k a good responder to treatment: for each analyte k, I have two 20 pt x 12 measurement matrices (one for placebo, one for control).
I think it makes sense that I would get different results if I on the one hand 1. average all 12 measurements into a single value 2. compare by means of a paired t-test the 20 average analyte k levels for drug vs. 20 average analyte k levels for placebo (note I am not making use of the variance of the 12 measurements here) OR on the other hand compare the placebo 20 x 12 matrix vs. the drug 20 x 12 matrix element by element (the latter method would retain the variability of each vector of 12.
I’m actually not sure which analysis method would be best to compare these 20-pt x 12-measurement matrices (Hotelling, ANOVA?)
B. For each patient i, is there an overall “biochemical response”? i.e. For each patient i, there are 7×12 analyte levels measured that I want to compare in the placebo vs. drug conditions. As before I can average out the 12 measurements and compare the 7D vector of analytes’ average levels for placebo vs. drug using a paired t-test for each patient i. This method again would lose the variability information present in the set of 12 measurement.
Alternatively, using the raw data per patient i: 12×7 (placebo) vs 12×7 (drug), I believe a suitable test in this case is an *unpaired* samples Hotelling’s T^2 test (12 rows for the 12 measurements and 7 columns for the 7 analytes just as you did in the example on this page – where instead of 7 analytes you had 3 indicators of health: pain, pressure, and fever)
C. Does the drug lead to a statistically significant “biochemical response”? i.e. 20 rows of patients x 7 cytokines x 12 measurements compared placebo vs. drug.
One way (again losing the variability information in all vectors of 12) is to average all 12 into one value (average analyte level per patient per analyte type), make a 20-row, 7-column matrix for placebo and another 20×7 for drug, and compare using a *paired* Hotelling’s test.
If I wanted however to retain the variability information, I would have to compare a 3D matrix for placebo (20x7x12) with a similar 3D matrix for drug. If the Student’s t-test compares (1D) vectors (samples of population) across and Hotelling’s compares (2D) matrices, is there a higher-level test that compares 3D matrices?
Hope this makes the experiment and the questions asked clear.
regards,
Cristian
Cristian,
Thanks. This is much clearer now, although I have a couple of questions.
1. Why are 12 measurements taken? Is there any difference between them or should I simply expect random fluctuation due to measurement error.
2. In C you use the term “7 cytokines” whereas elsewhere you use the term “7 analytes”. Is there a difference between these two terms?
3. In the first paragraph of B you mention using a “paired t test”. Do you mean “paired Hotelling T-square test”? I ask since you still have 7 analytes to compare even if you average the 12 measurements (unless I am missing something)?
Charles
I also wonder how the one-tailed or two-tailed t-distributions translate in the 2D (Hotelling’s) case. In the example provided I am interested in calculating the “one-tailed” p-value – the probability that the 7 analytes’ levels (pooled together) increase statistically significantly given the measured data.
regards,
Cristian
Hi Charles,
thanks for taking the time to read through my example.
I’ll answer your questions below – the 12 measurements are done in this way because of the experimental method – it involves placing 12 small (microliters) samples from the blood sample drawn from a given patient in separate wells. Each well is then subjected to an radioactivity-based assay which then reports the concentrations of the 7 analytes (cytokines) in each well. As you guessed yourself, the variation between wells is essentially random, although as an added complication not just because of experimental error but also because each of the wells contains a variable number of cells. Each cell can produce a variable amount of analyte, but to simplify things it is easier to assume that log(c) ~ N(mu, sigma^2), where mu is taken to be the log-concentration of the analyte in blood and sigma is the variability of the 12-well samples.
The analytes in question are a class of proteins named cytokines but I avoided mentioning that to avoid complicating things – but it looks like I missed in one spot.
Finally regarding the last question – I wouldn’t use a Hotelling test here because there is no one-to-one correspondence between the wells (they are all equivalent samples drawn from one larger blood sample). I was referring at simplifying the analysis by discarding half the data, namely the variability component between the 12 wells: test to be done is comparing 7 analytes x 12 samples (before drug treatment) vs. 7 analytes x 12 sample (after drug). Since the 12 measurements are equivalent and interchangeable I was proposing taking their average and doing a paired t-test between the 7 analytes x 1 average of 12 (before) vs. 7 analytes x 1 average of 12 (after). This method effectively discards half the information (within sample variance). I was instead looking for a method that actually compares 7 analytes x (mean +/- S.E.M. of 12 measurements) vs 7 analytes x (mean +/- S.E.M. of 12 measurements) or possibly 7 x12 vs 7 x 12.
regards, Cristian
Cristian,
Thanks for the explanation. When you said that you were discarding half the information, I assumed that you were discarding half the data or half the samples. I see that this is not what you meant.
Since you are ignoring the variability between the wells, it seems to me that essentially you have a two factor ANOVA with one fixed factor (the 7 analytes)and one repeated measures factor (time: before vs after treatment). There are then 12 measurements for each of the 7 x 12 cells; these are the replicates.
This scenario can then be analyzed using the approach described in the webpage
https://real-statistics.com/anova-repeated-measures/one-between-subjects-factor-and-one-within-subjects-factor/
You could use the Real Statistics Repeated Measures: mixed data analysis tool.
I haven’t thought much about the simplification to a paired t test, but my gut feeling is that you are throwing too much information away. If instead you meant a paired Hotelling’s T-square test, where the dependent vectors are the measurements for the 7 analytes, this seems to be a reasonable approach if you expect there to be correlations between the analytes.
Charles
Hi Charles, thanks for the response.
I too have considered a multi-factor ANOVA and a Hotelling T^2-test – in fact I had initially done the analysis using the Hotelling test. Since my data was 12 measurements x 7 analytes (7 dependent variables) x 2 drug conditions it seemed suitable, until I realized that I could interchange for example measurement 1 of analyte 1 with measurement 2 of analyte 1, both before drug treatment, and I should in principle get the same result – for any given analyte, all 12 measurements are equivalent because they are all drawn from the same population, namely the p.d.f. of that analyte’s concentration.
Hotelling’s test however treats the 7×12 as a matrix and the covariance matrices that are calculated involve sums of the form Sum (x_ij – x_i)*(y_i’j – y_i’) where the summation is performed over all j’s =1..12 for any i=1..7, i’=1..7. You can see that if you do do the interchange I mentioned you would not get the same covariance matrix (i.e. try interchanging x_ij with x_ij’ but not doing so for y_i’j with y_i’j’). Hope I’m making this clear. Essential if the 12 items were patients – the same patients across all i’s, Hotelling would be the way to go, because the data would be paired across j’s. But in this case each j refers to one of the 12 measurements done for analyte i, which has nothing to do with the index of j for the 12 measurements done for analyte i’ (i i’).
If you want to look at factors as “ordinal” (my way of calling them, not sure if that’s the established terminology), then the i axis is ordinal – the analytes have a defined identity and cannot be interchanged, and the j axis is not ordinal. Therefore the 7×12 object you are dealing with is not really a matrix, but a 7D-vector of sets of 12 measurements, i.e. the latter is not a 12D-vector but just a (non-ordinal or equivalent) collection of 12 items.
I think this is really the issue here, because all the methods I’ve seen and that you mentioned (Hotelling, ANOVA) do seem to treat the 12 measurements of analyte i to correspond on a one-to-one basis to the 12 measurments of analyte i’. E.g. the link you provided describing one-between-subjects one-within-subjects, the first figure on the webpage (Fig. 1), all the data for days 1-5 on row 4 refers to a specific patient, and row 5 refers to another patient. I cannot in that case therefore interchange e.g. cells B4 with B5 and expect to get the same result – I would have to interchange B4 with B5, C4 with C5, D4 with D5, etc – the entire row 4 with row 5.
So I guess I’m just wondering if there is indeed a test that’s established for this sort of problem – I would think there is since it is relatively straightforward, but so far haven’t seen anything in the lit that falls spot on.
Also, I agree with you that doing a paired t-test and discarding the variances of the 12 measurements is an oversimplification, I was looking for maybe an extension of the paired t-test where it’s not just absolute numbers that are compared 7D vs. 7D, but (essentially) a 7D-vector of populations vs. another 7D vector of populations. If normality is assumed, that would be comparing a 7D vector containing elements of the (mean_for_analyte_i +/- SEM) vs. another 7D element of the same sort. A simple t-test would just compare 7D-vectors of (mean_for_analyte_i).
regards,
Cristian
Cristian,
I don’t have anything more to say, except that I will be introducing new tests in the future, one of which may be useful for this problem.
Charles
I think a good summary of the above is that whatever the test that I’m looking for is, it should be invariant w.r.t. interchange of x_ij with x_ij’, for all j not equal to j’, for all i=1..7, but it should NOT be invariant w.r.t. interchange of x_ij with x_i’j. I believe neither Hotelling nor ANOVA satisfy that.
Hi Charles,
Ok.
thanks for your help.
regards,
Cristian
pls am writing a project to deteermine the effect of three brands of poultry feed on the weight of the poultry birds in two groups of birds. i want to used anova and hotelling ,how will i use hotelling to check on the vector mean of the two group since my data was collected on a weekly base and 60 chicken were used 30 for each group then i sub divide it again into 10 per brand of feed in each group.thank you
If your only dependent variable is weight, why can’t you simply use 2 factor ANOVA where factor A = brand of poultry and factor B = bird group?
Charles
Do these tests are efficient in large observation setup (like 1million observation)
Usually, the more observations the more accurate the test, although the more likely a significant result will be detected.
Charles
i want to group my 403 sample geographically,that is not equal,and find out the pre visit and post visit experience in 8 factors with different geographically disributed foreign tourist seperately,to find out the significant difference,,please help me,in spss or excel,is there any option to do this,hotelling t2..
The Real Statistics software provides a number of data analysis tools for carrying out Hotelling’s T-square Test in Excel. For me to be more precise you need to provide a more complete picture of the problem you are trying to solve.
Charles
how can i use hotelling t2 test of my collected data, i collected 403 samples of foreign tourists continent wise in one tourist destination,to find out pre visit expectation and post visit experience and have to find out difference level with 8 same types expectation and experience factors.in SPSS How can i use this hotelling t2 test,pls help me,and mail me, at —- ahmad.wasim1984@gmail.com
Wasim,
This sounds like a repeated measures test. Please see the following webpage
https://real-statistics.com/multivariate-statistics/multivariate-repeated-measures-tests/
Charles
Hi Charles,
would you mind to share the excel sheets you used in example 1?
Because somehow I cannot reproduce the same results as you have shown in figure 2.
I have already double checked the formulas used and also the input.
Thanks in advance!
You can download this Excel sheet by going to the webpage
Real Statistics Examples Workbooks
Charles
the pressure,aches,fever . what are they measured in? is it mg or gram.
The test is the same whether it is mg, grams or any other units.
Charles
How many subjects do I need in comparison to the number of variables? More specifically, if I have treatment versus control time-series measurements at 10 time points, how many subjects do I need in each group (treatment and control) to use the Hotelling test (Theorem 2)?
Greg,
If you mean how many subjects do you need to obtain sufficient power, then you can use G*Power to find this out. I will eventually add this capability to the Real Statistics Resource Pack, but for now you can use the G*Power tool.
Charles
well done MR charles… my question is why do we use f-distribution instead of other distribution?
Alfred,
Essentially this test is equivalent to testing whether there is a significant difference between two variances. This is what the F distribution is designed to do. This is why this distribution is also used in ANOVA and regression.
Charles
Please Mr Charles i’m writing my project on this topic.please ii need help
Alfred,
What sort of help do you need?
Charles
How to write a project on this topic
Alfred,
I am happy to answer specific questions, but I am not in a position to help you write a project.
Charles
I know just a tip. That what I need
Sorry Alfred, but this is such a wide topic that I don’t really have any tip that I can give.
Charles
Can Hotelling’s T-squared test be used for three or more samples or just two? Thank you.
Garrett,
Just two. With three or more, you can use MANOVA instead.
Charles
Year Malaria Rainfall
2002 6500 63
2003 18006 178
2004 16078 172.0
2005 1965 168.4
2006 9156 283.6
2007 3880 256.7
2008 2135 225.3
2009 1635 103.6
2010 8317 374.3
2011 1529 308.1
2012 831 231.5
2013 549 200
2014 92 148
How to analysis these data? Malaria v/s Rainfall in particular place.
What is the possible way to analysis these data? Malaria v/s Rainfall in particular place.
There are many ways to analyze this data. What hypothesis do you wish to test?
Charles
Dear Charles,
I am writing a short paper for my school on the Hotelling’s T-square, and I was wondering whether I can use data that is provided in this page?
Thank you very much,
Hsiu Yen
Hsiu Yen,
Yes, you can use data provided on the webpage. You can reference the website as described on the webpage Citation.
Charles
Good afternoon Charles,
I am giving a student presentation on Hotelling’s T for my chemometrics class. I was wondering if I could use one of your examples in my presentation.
Thanks for your time!
Tricia,
Yes, please feel free to use one of my examples for your presentation.
Charles
Hi Tricia- I’m trying to understand Hotelling’s Tsquare as it is the recommended analysis for my dissertation, but its not in any of my stats texts. I was wondering if you would share your presentation on it?
Thanks for your consideration
Erin
I am really passing first time good comment due to excellent data provided for presentation purpose.
Hi. Just wanted to check would you use a Hotelling T2 test (multi variate form) to explore the differences between two groups on a large number of rating scales. For example, to compare a typical with an atypical population on multiple questionnaires and observed behaviour scores.
Regina,
I would need more information to give a definitive “yes”, but it sounds like Hotelling T2 could be a good choice.
Charles
Hi,
Please help what to do with this problem:
The IQ’s and EQ’s of male and female students were obtained and compared. test the hypothesis that male and female students have equal IQ’s and EQ’s simultaneously.
Thanks a lot.
Hi,
The Hotelling T-square test seems to be a good choice for performing this analysis. I suggest that you read the referenced webpage.
Charles