Jenks Natural Breaks optimization addresses the problem of how to split a range of numbers into contiguous classes so as to minimize the squared deviation within each class.
Example
Example 1: Define 4 classes for the data in Figure 1 which achieves this objective.
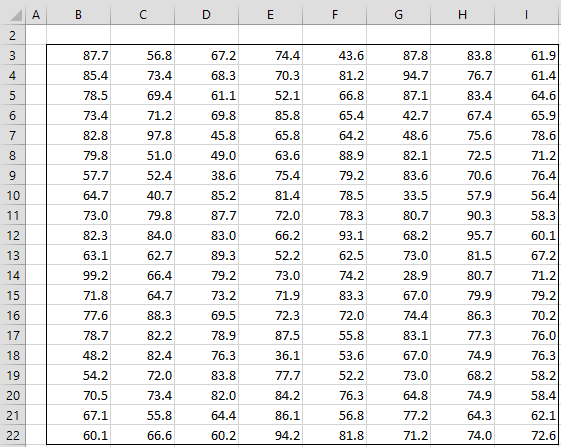
Figure 1 – Data for Example 1
Suppose, for example, that we simply divide the 160 elements in Figure 1 into four intervals each containing 40 elements, as shown in Figure 2.
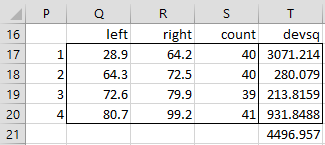
Figure 2 – Equally spaced intervals
Here, for example, cell Q18 contains the formula =SMALL($B$3:$I$22,40*(P18-1)+1), cell R18 contains the formula =SMALL($B$3:$I$22,40*P18) and cell S18 contains the formula
=COUNTIFS($B$3:$I$22,”>=”&Q18,$B$3:$I$22,”<=”&R18)
Note that cell R19 should contain the 120th smallest element in Figure 1, which is 80.7, but since 80.7 is also the 121st smallest element, this would split 80.7 between interval 3 and interval 4. This is why we are forced to make interval 3 slightly smaller and interval 4 slightly bigger.
The squared deviation of each of the four intervals is found in range T17:T20, with the sum in cell T21. Note that cell T17 contains the array formula
=DEVSQ(IF($B$3:$I$22>=Q18,IF($B$3:$I$22<=R18,B4:I23,””),””))
What we don’t know is whether this choice of four intervals is the partition of the full range that results in the smallest sum in cell T21. As we will see shortly, the optimum solution, using Jenks Natural Breaks optimization, is shown in Figure 3. As you can see, this is a better solution than the one shown in Figure 2 (since 3107.102 < 4496.957).
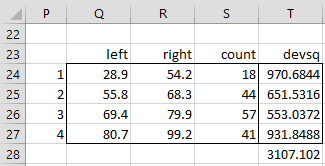
Figure 3 – Optimal partition
Small Example
Example 2: Find the optimal partition of the values 5, 8, 9, 12, and 15 into 3 classes.
Since this is a simpler problem than the one in Example 1, we are able to evaluate all six possible solutions, as shown in Figure 4.

Figure 4 – Jenks Natural Breaks
In the first possible solution, shown in range B3:D7, the three classes are 5, 8, and 9-15. The squared deviation for the third category (cell D6), for example, is calculated by the formula =DEVSQ(D3:D5), with a total for all three classes of 18, using the formula =SUM(B6:D6).
We see from Figure 4 that the optimal partition is the second one, with classes 5, 8-9, and 12-15 since the total squared deviation of 5 is less than that of the other partitions.
The value of 5 is repeated in cell AA4 in order to calculate the goodness of variance fit (GVF), which is calculated as
GVF =

where d* is the minimum total squared deviation, as described above, and d is the squared deviation of the data set, which for Example 2 is 58.8 (cell AA3) as calculated by the formula =DEVSQ(F3:H5). GVF takes a value between 0 and 1. The closer to 1 the better the fit.
Iterative Approach
In Example 2, we were able to go through each possible partition and calculate its squared deviation. While in Example 1, this is too time-consuming to do manually, we can use the Real Statistics Jenks Natural Breaks data analysis tool, as described below, to do the calculations for us, for other problems the number of possible partitions is even too time-consuming for the computer to do.
For example, there are 8,301,429,675 ways to partition 254 data elements into 6 classes. This number gets even larger the more data elements there are and the more classes we want to use. In such cases, we will need to use an iterative approach. In particular, we select a partition at random and see which class has the largest squared deviation and which class has the least squared deviation.
If, for example, we used 6 classes and class 3 had the largest squared deviation and class 5 had the smallest squared deviation, then we would move the last element in class 3 into class 4 (in the direction of class 5). If instead, class 3 had the largest squared deviation and class 1 had the smallest squared deviation, then we would move the first element in class 3 into class 2.
We repeat this process again and again, continuing until the squared deviations of none of the classes changed or until a maximum number of iterations had been reached, at which point we would select the partition with the lowest total squared deviations. In order to avoid a local minimum, from time to time we could make a random perturbation.
Data Analysis Tool
Real Statistics Data Analysis Tool: The Real Statistics Resource Pack provides the Jenks Natural Breaks data analysis tool to perform the optimization automatically.
To perform the analysis for Example 1, press Ctrl-m and select Jenks Natural Breaks from the Multivar tab. If you are using the original user interface, then instead choose the Multivariate Analyses option from the main menu and then select Jenks Natural Breaks from the dialog box that appears.
In either case, the Jenks Natural Breaks dialog box will now appear. Fill in the various fields as shown in Figure 5 and press the OK button. If you leave the Number of Iterations field blank then the algorithm will evaluate all possible partitions.
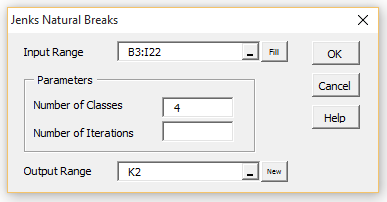
Figure 5 – Jenks Natural Breaks dialog box
The result is shown in Figure 6.
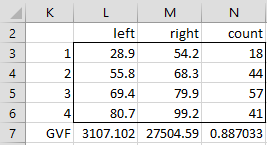
Figure 6 – Jenks Natural Breaks data analysis
Here 3107.102 (cell L7) represents the total squared deviation for the partition found using the Jenks Natural Breaks algorithm, 27504.59 (cell M7) is the squared deviation of the input data, as calculated by =DEVSQ(B3:I22), and 88.7% is the GVF (cell N7), as calculated by the formula =1-L7/M7.
As described earlier, for large data sets or a large number of classes (especially 6 or 7 or greater), you should usually use an iterative approach by filling in the Number of Iterations field with a number such as 10000 or 250000 to specify the maximum number of iterations. Figure 7 contains the output for Example 1 with 100,000 iterations.
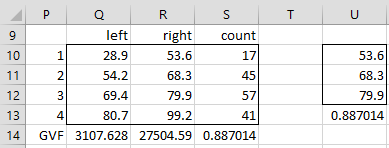
Figure 7 – Iterated version of Jenks Natural Breaks
Note that the GVF of .887014 is only slightly lower than the optimal solution shown in Figure 6. Note too that if you run the algorithm again with 100,000 iterations, you may get a slightly different solution.
Worksheet Functions
Real Statistics Functions: The Real Statistics Resource Pack provides the following functions.
JENKS(R1,, lab, iter) – performs Jenks Natural Breaks optimization on the data in range R1 for k classes and outputs a k+1 × 3 range, whose first k rows contain the left and right endpoints of each of the classes followed by the number of elements in the class. The last row contains the total squared deviation of the k classes, followed by the squared deviation for the data in R1 and GVF.
Here k+1 = the number of rows in the highlighted output range. If iter is included then the algorithm uses iter iterations, otherwise, all possible partitions are tested. If lab = TRUE (default = FALSE) then an extra column of labels is included.
The range K3:N7 of Figure 7 contains the output of the array formula =JENKS(B3:I22,,TRUE). The range P10:S14 of Figure 8 contains the output of the array formula =JENKS(B3:I22,,TRUE,100000).
There is also a short form of the JENKS function, which explicitly identifies the number of classes k:
JENKS(R1, k, lab, iter) – outputs a k × 1 column range, whose first k−1 rows contain the right endpoint of the first k−1 classes (the endpoint of the kth category is the largest element in R1) and whose last element is the GVF.
The range U10:U13 of Figure 7 contains the array formula =JENKS(B3:I22,4,,100000).
GVF(R1, R2) = GVF for the right endpoints (breaks) in range R2 based on the data in column range R1.
Coloring Maps
The Jenks Natural Breaks algorithm is commonly used to color maps as shown in Figure 8.
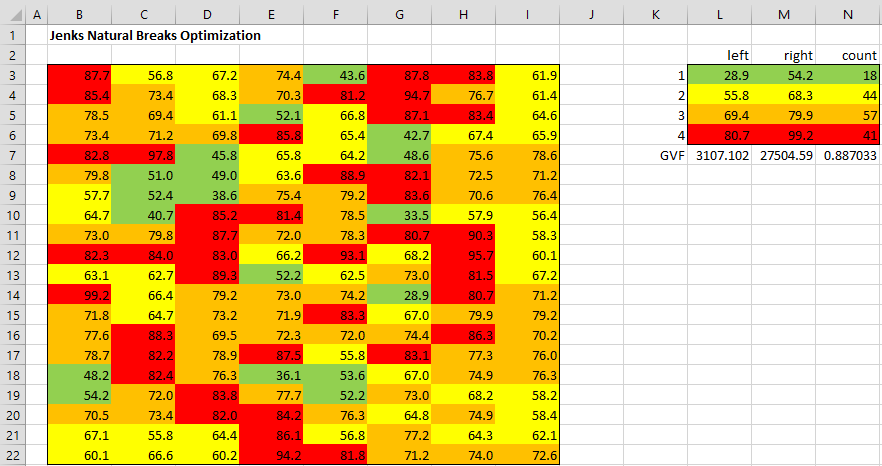
Figure 8 – Maps using Jenks Natural Breaks
Here, we use green for those cells in class 1, yellow for class 2, orange for class 3, and red for class 4 of Example 1. You can accomplish this using Excel’s conditional formatting capability. For example, to format the cells in category 1,
- Highlight range B3:I22
- Select Home > Styles|Conditional Formatting > New Rule…
- In the New Formatting Rule dialog box, click on Use a formula to determine which cells to format
- Under Format values where this formula is true, type the formula =AND(B3>=L3,B3<=M3)
- Click the Format… button
- In the Format Cells dialog box, click on the Fill tab, and choose the Green color
- Click the OK button on this dialog and on the next dialog box that appears
You can repeat this procedure to format the other three classes.
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
References
EHDP (2015) Jenks natural breaks explained
https://www.ehdp.com/methods/jenks-natural-breaks-2.htm#:~:text=What%20is%20%22Natural%20Breaks%22%3F,should%20have%20the%20same%20color.
Excel Easy (2016) Conditional formatting
https://www.excel-easy.com/data-analysis/conditional-formatting.html
Dear Charles,
thanks a lot for letting us use your extensive statistical knowledge. You should be proud of helping so many people all over the world.
I just noticed that in the phrase “Note that cell R3 should contain the 120th smallest element in Figure 1, ” in Jenks Natural Breaks page, you reference to “cell R3” should instead be to “cell R26”. Am I right?
Once again thanks
Thank you for your kind words, Paulo.
The reference to cell R3 should be R19.
Thank you for catching this error. I have now made the correction on the webpage.
Charles
Hi,
Can I have your email address to discuss this method further please. And I would like to give you an overview of my data to see if it is possible to use the Natural break.
See Contact Us
Charles
Hi
I am very grateful for the content of your page, it has helped me a lot.
I would like to ask how I can cite its content in a thesis document, particularly Jenks’s section.
Thanks a lot
Hi Patricia and thanks for your kind words.
See the following webpage regarding the citation
Citation
Charles
I have been looking for information about this method for some time and this is the first I have found with an example, thank you for that. I’m a software developer and I’m working on a tool for a GIS that shows information in a thematic map using this classification method, but I’ve had some doubts. Could I contact you by any means to expose you some questions I have?
Cristian,
You can send me an email. You can find my email address at Contact UsContact Us.
Charles
Great product! Easy installation and works just as advertised. Thank you so much for making this free and available for download.
thank you for your excellent product .
I used your macro but in defining classes of my data the upper limit of some classes are overlapping with the next class.
Is it reasonable? in such case How can I do ?
If I understand correctly, this shouldn’t happen. If you email me an Excel file with your data and results, I will try to figure out what is going on.
Charles
Thank you for sharing the novel macro in Excel. I have two questions:1) Why for my data in some cases of classification the upper level of a class overlaps the lower level of next class? 2) There are some gaps between adjacent classes, is it acceptable ?
Hello Mojtaba,
If you email me an Excel file with your data and results, I will try to answer your questions.
Charles
We are developing a tool to help our faculty write multiple choice questions. There are at least 27 different flaws that can be made and we want to construct a table of the most common ones that our faculty make and provide it to them as a resource to use when creating tests. To develop that tool we are going to evaluate a random sample of questions written by our faculty for each of the 27 flaws. That will create a frequency for each flaw. I am wondering to generate a list of the MOST common could I then run the Jenks natural breaks and use two categories (common/uncommon) to identify where to break the dataset and which flaws to include in our tool (common), and which to ignore (uncommon)?
Hi Paul,
I think this will work.
Charles
Thank you for such a nice tool.
I’d like to ask you that.. I’m getting a message “Unable to get Frequency property of the WorksheetFunction class” inconsistently. I mean I’m trying to use ‘Jenks Natural Breaks Optimization’ for about 150,000 data. Some are classified well, but for other some I’m getting the error message. I don’t see any difference in data.
If you email me an Excel file with your data and the results you got, I will try to figure out what is happening.
Charles
Great service you provide, worked as described. My question is how does one judge the reasonableness of the breaks or grouping. If I increase the number of classes the GVF improves even if it is clear that I have “overspecified” the number of groups. Is there a way to “penalize” GVF for the number of groups or even better is there a routine which returns the groups that “best” describes the data? So, for instance, (8,9,10,11,12,48,49,50,51,51,98,99,100,101,102) should yield groups = 3 as the optimal grouping solution.
Bruce,
I don’t know of a way to penalize GVF’s based on the number of groups (as, for example AIC does for linear regression). The only advice I can give is:
1. For some problems, there is a natural number of categories/groups based, not on mathematics, but on the natural of the real world situation.
2. On approach that you might want to use as the one used in Factor Analysis based on the Scree chart. For Jenks, create a graph whose x axis is the number of groups (with values, say, 2, 3, 4, 5, 6, 7 — or less if the Jenks algorithm takes too long to run with such high values) and whose y value is the corresponding GVF value. Then look for where the curve flattens out, indicating that you are getting “less bang (i.e. GVF improvement) for the buck (i.e. the expense of using more categories).
Charles
Why do my numbers keep changing after I run Jenks Natural Breaks when I go to click on other cells? The numbers in the output keep shifting…Any ideas?
Sam,
This is because this data analysis tool uses a random number generator, actually Excel’s RAND() function, and so the results change when you click on other cells. You can stop this from happening by copying the output and then pasting-special values. This is done by highlighting the output, pressing Ctrl-C and then selecting Paste-Special and choosing Values (or alternatively by pressing Ctrl+F10 and then pressing V).
Charles