Basic Concepts
Suppose that X = (x1, …, xk)T is a k-tuple of random variables. X has a multivariate normal distribution N(µ, Σ) if the joint probability density function can be expressed as
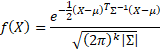
Here Σ is the k × k population covariance matrix, µ = (µ1, …, µk)T is the population mean vector and |Σ| is the determinant of Σ. Note that the exponent of e consists of a scalar times the transpose of X – µ, the inverse of Σ and X – µ, which has dimension (1 × k) × (k × k) × (k × 1) = 1 × 1, i.e. a scalar. Thus, f(X) is a number.
If we partition X as
![]()
where X1 is k1 × 1 and X2 is k2 × 1 (and so k1 + k2 = k), then we can partition the mean and covariance matrix in a similar fashion
![]()
Here µi is ki × 1 matrix and Σij is a ki × kj matrix. We need to use the following two properties:
Properties
Property 1: Xi has a multivariate normal distribution N(µi, Σii)
Property 2: A = X2|X1 has a multivariate normal distribution N(µ*, Σ*) with mean and covariance matrix
![]()
![]()
For a bivariate normal distribution
![]()
Thus![]()
![]()
Relationship to EM algorithm
From the first equation, we have the estimate for a missing y in the E step, as described in EM Algorithm for Bivariate Normal Data.
![]()
If Z has a multivariate normal distribution N(μ, Σ) and we partition Z as
![]()
where X = k × 1 . Then we can partition the mean and covariance matrix as described previously
![]()
Here ΣXX is a k × k matrix, ΣXy is a k × 1 matrix, ΣyX is a 1 × k matrix and Σyy is a scalar
Then A = y|X has a multivariate normal distribution with mean and covariance
![]()
![]()
Thus, we estimate the missing y value corresponding to X0 (E step in the EM algorithm) by the formula
![]()
where![]()
i.e. the sample means vector and covariance matrix (M step in the EM algorithm).
We show how this is done in EM Multivariate Normal Data with Missing Elements.
Links
References
Wikipedia (2018) Multivariate normal distribution
https://en.wikipedia.org/wiki/Multivariate_normal_distribution