Fitting data to a distribution
We can also apply the chi-square goodness of fit test (both the Pearson’s and maximum likelihood versions) to determine whether observed data fit a certain distribution (or curve). For this purpose, we employ the following modified version of Property 1 or 2 of Goodness of Fit.
Property 1: Where there are m unknown parameters in the distribution or curve being fitted, the test statistic in Property 2 of Goodness of Fit has approximately the chi-square distribution χ2 (k–m–1).
Thus when fitting data to a Poisson distribution m = 1 (the mean parameter), while if fitting data to a normal distribution m = 2 (the mean and standard deviation parameters).
Goodness-of-fit example
Example 1: A substance is bombarded with radioactive particles for 200 minutes. Between 0 and 7 hits were observed in any one-minute interval, as summarized in columns A and B of the worksheet in Figure 1. Thus for 8 of the one-minute intervals, there were no hits, for 33 of the one-minute intervals, there was 1 hit, etc.

Figure 1 – Example data plus chi-square calculation
We hypothesize that the data follows a Poisson distribution whose mean is the weighted average of the observed number of hits per minute, which we calculate to be 612/200 = 3.06 (cell B14).
H0: the observed data follows a Poisson distribution
For each row in the table, we next calculate the probability of x (where x = hits per minute) for x = 0 through 7 using the Poisson pdf, i.e. f(x) = POISSON.DIST(x, 3.06, FALSE), and then multiply this probability by 200 to get the expected number of hits per interval assuming the null hypothesis is true (column D). For example, cell D4 contains the worksheet formula =POISSON.DIST(A4,$B$14,FALSE)*B$12.
Analysis
We would like to proceed as in Example 3 of Goodness of Fit, except that this time we can’t use CHISQ.TEST since df ≠ the sample size minus 1. In fact, df = k – m – 1 = 8 – 1 – 1 = 6 since there are 8 intervals (k) and the Poisson distribution has 1 unidentified parameter (m), namely the mean. We, therefore, proceed as in Example 2 of Goodness of Fit, and explicitly calculate the chi-square test statistic (in column F) to be 3.085. We next calculate the following:
p-value = CHISQ.DIST.RT(χ2, df) = CHISQ.DIST.RT(3.085,6) = .798 > .05 = α
χ2-crit = CHISQ.INV.RT(α, df) = CHISQ.INV.RT(.05,6) = 12.59 > 3.09 = χ2-obs
Based on either of the above inequalities, we retain the null hypothesis, and so with 95% confidence conclude that the observed data follow a Poisson distribution.
Worksheet Function
Real Statistics Function: The Real Statistics Resource Pack provides the following function to handle analyses such as that used for Example 1:
FIT_TEST(R1, R2, par) = CHISQ.DIST.RT(χ2, df) where R1 = the array of observed data, R2 = the array of expected values, par = the number of unknown parameters as in Property 1 (default = 0), and χ2 is calculated from R1 and R2 as in Definition 2 with df = the number of elements in R1 (or R2) – par – 1.
For Example 2 of Goodness of Fit, FIT_TEST(B4:G4,B5:G5) = CHISQ.TEST(B4:G4,B5:G5) = .0297 and for Example 1, FIT_TEST(B4:B11,D4:D11,1) = .798.
Observation: See Chi-square Goodness-of-Fit Test and Goodness-of-Fit Analysis Tools for additional information about how to use Real Statistics capabilities to perform a chi-square goodness-of-fit test for specific distributions.
Testing using the index of dispersion
As we saw above, we can use Property 1 to determine whether data follow a Poisson distribution. Note that if we want to test whether data follow a Poisson distribution with a predefined mean then we can use Property 2 of Goodness of Fit instead, and so don’t need to reduce the degrees of freedom of the chi-square test by one.
We can also use the index of dispersion (described at Poisson Distribution) to test whether a data set follows a Poisson distribution.
Definition 1: The Poisson index of dispersion is defined as
![]()
Since the index of dispersion is the variance divided by the mean, the Poisson index of dispersion is simply the index of dispersion multiplied by n−1. We can calculate the Poisson index of dispersion for the data in R1 using the Excel formula =DEVSQ(R1)/AVERAGE(R1).
Property 2: For a sample of sufficiently large size n and mean ≥ 4, the Poisson index of dispersion follows a chi-square distribution with n–1 degrees of freedom.
The estimate is pretty good when the mean ≥ 4 even for values of n as low as 5. Thus the property is especially useful with small samples, where we don’t have sufficient data to use the goodness-of-fit test described previously.
Poisson Index of Dispersion Example
Example 2: Use Property 2 to determine whether the data in range A3:B8 of Figure 2 follows a Poisson distribution.
As we can see from the analysis in Figure 2, we don’t have sufficient reason to reject the null hypothesis that the data follows a Poisson distribution.
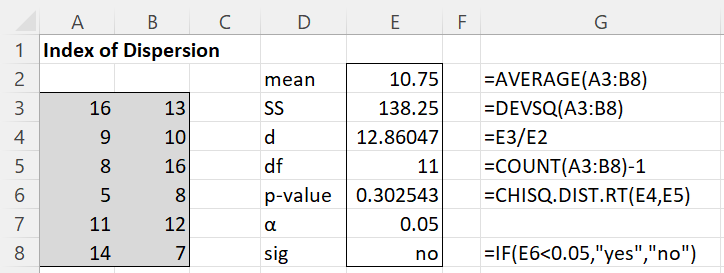
Figure 2 – Testing using Poisson Index of Dispersion
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
References
Zar, J. H. (2010) Biostatistical analysis 5th Ed. Pearson
Agresti, A. (2013) Categorical data analysis, 3rd Ed. Wiley.
https://mybiostats.files.wordpress.com/2015/03/3rd-ed-alan_agresti_categorical_data_analysis.pdf
Howell, D. C. (2010) Statistical methods for psychology (7th ed.). Wadsworth, Cengage Learning.
https://labs.la.utexas.edu/gilden/files/2016/05/Statistics-Text.pdf
Charles,
I would appreciate your help in using the Chi-square distribution. I repeated Example 1 with each observed count multiplied by 100, and expected this should not affect the conclusions. However, this change resulted in a Chi-square test stat of 308.5, 100 times that of the original data. The critical Chi-square for alpha 0.05 remained 12.59, and the Fit_test p << 0.001. What did I do wrong? Thanks.
Hello Dave,
It is a good question, and I can see why your intuition might point you in that direction. But…
There isn’t any reason to believe that when you multiply all the elements in a sample that follows a Poisson distribution by 100 you will still get a sample of a Poisson distribution. For example, a key characteristic of a Poisson distribution is that the mean = the variance. If you multiply all the elements of a sample from a Poisson distribution (where the mean is approximately equal to the variance) by 100, you should expect that the variance of the resulting sample will be a lot bigger than the mean of the sample.
Charles
Charles,
I calculated the variance for the observed counts in Example 1 to be 3.00, which is close to the mean of 3.06, as you pointed out. When the counts are multiplied by 100 and keeping the same proportions, the mean remains 3.06 and the variance is 2.99. So I think it is still reasonable to compare the 100X data to the Poisson model. I see that the Chi-square stat increases with total counts because (O-E)2 increases faster than E, but don’t understand why collecting more data from the same population increases the probability of rejecting the null hypothesis that the data follows the Poisson distribution. Is there another way to test the goodness-of-fit that doesn’t penalize collecting more data? Thanks.
Dave,
1. In general, increasing the amount of data increases the likelihood of obtaining a significant result, which in this case would mean rejecting the null hypothesis that the data follows a Poisson distribution. The reason for this is that with a large sample even a small deviation from Poissonity would be detected. With a small sample the amount of deviation would have to be much larger to reject the null hypothesis. This observation holds for all statistical tests, which is the reason why increasingly we look at other metrics, especially effect sizes and confidence intervals, instead of just p-values.
2. One way to see this is to select data that actually follows a Poisson distribution exactly. In this case, the counts won’t be integers, but what you will see is that chi-square statistic will be zero resulting in a p-value of 1. If you multiply all the counts by 100, you will get the same result. Now you can depart slightly from exact Poissonity and see at which total number of observations you get a significant result.
3. I haven’t found much information about alternative tests, but the following paper may be useful
https://digitalscholarship.unlv.edu/cgi/viewcontent.cgi?article=2606&context=rtds
Charles
Dave,
I forgot to add the following references that I found earlier:
https://search.r-project.org/CRAN/refmans/energy/html/poisson.html
https://www.journals.ac.za/sasj/article/download/4991/3159
Charles
Charles,
Thank you for clarifying the effect of increasing the amount of data on rejecting the null hypothesis, the value of using effect size and confidence intervals, and for the references. The references appear to be very useful and will help me understand the Chi-square test.
Dave